





I. Introduction▲
Ce REX a été mis en place afin de décrire la procédure de création d'une architecture orientée microservice de toutes pièces. Il décrit les conclusions d'une étude technique réalisée chez Ippon, sous la tutelle de David Martin, directeur du pôle conseil et formation et travaillant chez Ippon Nantes, qui a, par ailleurs, écrit un article au sujet de l'avènement des microservices.
I-A. Définition d'un microservice▲
Le terme microservice jouit d'une popularité de plus en plus importante depuis le début des années 2010. Plusieurs définitions ont été établies depuis le temps, mais la plupart des experts en informatique s'accordent sur une même idée pour pouvoir décrire ce style d'architecture. Il s'agit d'une approche pour développer une application composée de plusieurs petits services, ayant chacun leur processus et utilisant des mécanismes de communication légers. Chacun de ces services doit pouvoir exécuter une partie unique et spécifique de l'application, et être déployé indépendamment des autres services. Il est important de noter que ces services peuvent être écrits dans des langages informatiques différents, et utiliser des systèmes de persistance qui le sont tout autant.
Adrian Cockroft, personnage influent dans le monde du cloud, a donné une définition concise de ce qu'est une architecture microservice, très répandue dans le domaine :
Loosely coupled service oriented architecture with bounded contexts.
Ce qui signifie en français : architecture orientée service à couplage faible dans un contexte confiné. Le couplage faible représente le peu de liens physiques entre les services. En ce qui concerne le contexte, il s'agit ici de démontrer qu'il y a bien isolation entre les différents métiers de l'architecture.
Certaines personnes iront même jusqu'à assimiler les microservices aux architectures de type SOA, à travers de nombreuses similarités entre les deux modèles, notamment le principe d'autonomie des services. Vous pourrez vous référer à cet article de Martin Fowler pour plus d'informations sur le concept des microservices.
I-B. De la théorie à la pratique▲
Alors que les discussions autour du potentiel d'un tel modèle ont continué de nourrir Internet, plusieurs personnes s'y sont intéressées de plus près, soit pour décrire le modèle, comme l'a fait Martin Fowler dans son article Microservices, soit pour le mettre en œuvre dans un contexte réel. Adrian Cockcroft, architecte cloud chez Netflix, a entrepris, en 2010, la mise en place d'une telle architecture au sein de l'entreprise. Devant un tel challenge, il décide donc de se pencher sur le tout nouveau modèle microservice pour étudier la viabilité de la méthode. Au terme de la mise en place de l'architecture chez Netflix, il déclarera que ce style d'architecture microservice s'assimile à du SOA plus précis.
Il fut l'un des premiers à utiliser le modèle microservice et à appliquer ce paradigme au sein de Netflix. De cette opération ambitieuse est né un mouvement de partage de logiciels open source très important de la part de la firme américaine, donnant naissance à Netflix OSS. C'est sur cette base de logiciels que notre architecture a été construite. Mais pas seulement…
Spring a aussi profité de cette nouvelle tendance pour enrichir son catalogue de services, avec la création du projet Spring Cloud, ayant pour vocation de rassembler les outils principaux à la création d'applications orientées systèmes distribués. Plusieurs modules composent ce nouveau projet, notamment Spring Cloud Netflix.
Et c'est donc la combinaison de ces deux projets Spring Cloud et Spring Cloud Netflix, et de la stack Netflix, qui va permettre de créer notre écosystème. Nous y ajouterons un système de persistance basé sur Apache Cassandra, ainsi qu'un système de logging avec la stack ELK.
II. L'application en tant que preuve▲
Afin de mieux assimiler le processus de création de l'architecture, plusieurs parties seront créées pour ce REX, et seront réparties sur la totalité des articles.
Pour bien comprendre le fonctionnement de l'architecture, il a été décidé de créer une application toute simple, permettant de démontrer le bon déroulement des opérations et l'intérêt de l'architecture.
- Product : représentant le produit en l'état ;
- Details : fournissant des informations sur les détails du produit ;
- Pricing : fournissant des informations sur les prix pratiqués pour la vente de ce produit.
Voici une représentation graphique des interactions entre ces trois services :
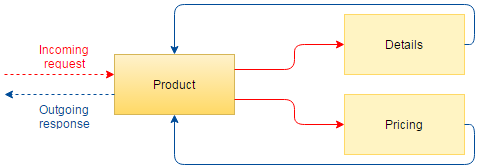
Product devient donc le point d'entrée de l'application, et en fonction de certains paramètres de la requête, il sera en mesure de savoir s'il faut requêter Details ou Pricing, ou les deux. Le but premier étant de faire communiquer trois entités différentes entre elles, nous ne parlerons pas, pour l'instant, de système de stockage de données.
La mise en place de ces services est donc facilitée par le créateur de projets REST Spring Boot. Cela va nous permettre de nous abstraire d'une certaine quantité de code étant donné que nous ne voulons, pour l'instant, qu'un service qui puisse recevoir une requête et soit la transmettre à un autre service, soit constituer la réponse et la renvoyer.
L'application est volontairement légère, car elle ne constitue pas la partie la plus importante de l'architecture. Le but est uniquement d'avoir une certaine quantité de services que l'on puisse utiliser et qui serviront à prouver le bon fonctionnement d'une architecture microservice.
Voici un exemple de service côté main et controller :
2.
3.
4.
5.
6.
7.
8.
@EnableAutoConfiguration
@SpringBootApplication
public class DetailsApplication {
public static void main(String[] args) {
SpringApplication.run(DetailsApplication.class, args);
}
}
2.
3.
4.
5.
6.
7.
8.
9.
@RestController
@RequestMapping("/details")
public class DetailsController {
@RequestMapping(value = "/{id}", method = RequestMethod.GET)
public DetailsDTO find(@PathVariable String id) {
/* do something here */
}
}
Chacun de ces services est donc reconnu par une adresse IP unique. Voici les IP attribuées ici, à titre d'exemple :
- Product : http://127.0.0.1:8080/products/ ;
- Details : http://127.0.0.1:8181/details/ ;
- Pricing : http://127.0.0.1:8282/pricing/.
Afin que Product puisse récupérer les informations depuis Details et Pricing, il faut lui fournir les adresses IP de ces derniers, ce qui rend le couplage très fort entre les services. En vertu d'une architecture microservice, il faut que les services puissent communiquer indépendamment les uns des autres, sans qu'ils aient besoin de se connaître.
C'est ici qu'intervient Eureka, le registre de services développé par Netflix, que nous utiliserons conjointement avec Spring Cloud dans le second billet de ce REX !
III. Eureka, registre de services au cœur de l'architecture▲
Maintenant que nous sommes familiers avec l'application qui servira de preuve pour l'architecture, nous allons commencer à implémenter une application qui va nous permettre de faire communiquer nos services entre eux sans qu'ils aient besoin de se connaître directement, grâce à Eureka.
III-A. Eureka, mais pour quoi faire ?▲
Eureka est une application permettant la localisation d'instances de services. Elle se caractérise par une partie serveur et une partie cliente. La communication entre les parties se fait via les API Web exposées par le composant serveur. Vous pouvez retrouver la documentation complète sur le wiki du dépôt Git d'Eureka. Ces services doivent être créés en tant que clients Eureka, ayant pour objectif de se connecter et s'enregistrer sur un serveur Eureka. De ce fait, les clients vont pouvoir s'enregistrer auprès du serveur et périodiquement donner des signes de vie. Le service Eureka (composant serveur) va pouvoir conserver les informations de localisation desdits clients afin de les mettre à disposition des autres services (service registry).
III-B. Mise en place du modèle client/serveur▲
Il convient donc de mettre en place un serveur Eureka et de transformer les trois services de notre application en clients Eureka. Fort heureusement, Spring Cloud et son projet supportant la plupart des applications de Netflix, ont intégré Eureka dans leur solution, créant ainsi deux annotations : @EnableEurekaServer et @EnableEurekaClient.
Ces deux annotations font partie du module spring-cloud-starter-eureka-server qu'il faut intégrer aux deux projets Spring Boot. Nous avons choisi d'utiliser Maven pour ce faire, et nous utilisons donc un fichier pom.xml pour chaque projet.
Reprenons le main de notre exemple de service pour le compléter :
2.
3.
4.
5.
6.
7.
8.
9.
@EnableAutoConfiguration
@SpringBootApplication
@EnableEurekaClient
public class DetailsApplication {
public static void main(String[] args) {
SpringApplication.run(DetailsApplication.class, args);
}
}
Il s'agit désormais de mettre en place le serveur Eureka afin de recevoir les informations des différents services, et de se placer au centre de l'architecture. Voici le main du serveur :
2.
3.
4.
5.
6.
7.
8.
@SpringBootApplication
@EnableEurekaServer
public class EurekaServer {
public static void main(String[] args) {
SpringApplication.run(EurekaServer.class, args);
}
}
Et voici un extrait des dépendances utilisées dans les deux services (le serveur et le client) :
2.
3.
4.
5.
6.
7.
8.
9.
10.
<parent>
<groupid>org.springframework.boot</groupid>
<artifactid>spring-boot-starter-parent</artifactid>
<version>1.2.2.RELEASE</version>
</parent>
<dependency>
<groupid>org.springframework.cloud</groupid>
<artifactid>spring-cloud-starter-eureka-server</artifactid>
<version>1.0.0.RELEASE</version>
</dependency>
Pour l'instant, il n'y a rien de compliqué concernant la mise en place de cette relation client/serveur. Aussi, notre exemple de service et le serveur Eureka ne peuvent pas encore communiquer, car notre service ne sait pas où se trouve le serveur Eureka. Il faut donc lui indiquer la localisation du serveur, et aussi configurer le serveur.
La configuration de ces deux applications se fait en utilisant un fichier YAML. On y configure notamment Eureka ainsi que le nom de l'application afin de l'utiliser plus tard comme identifiant de service :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
spring:
application:
name: details-service
eureka:
client:
serviceUrl:
defaultZone: http://127.0.0.1:8761/eureka/
instance:
leaseRenewalIntervalInSeconds: 10
metadataMap:
instanceId: ${spring.application.name}:${spring.application.instance_id:${server.port}:${random.value}}
Faisons désormais la même chose pour le serveur Eureka :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
spring:
application:
name: EurekaServer
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
L'ensemble de ces paramètres va permettre au serveur Eureka de se lancer, et à notre client Eureka de se connecter au registre des services et d'y inscrire ses informations. Pour vérifier que notre service est bien connecté à Eureka, il suffit d'aller regarder l'IHM créée par Spring à l'adresse http://127.0.0.1:8761. En voici un extrait :
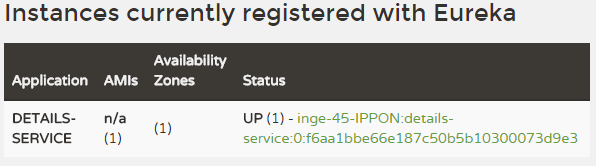
Pour le service Product, les choses se compliquent un peu plus. Rappelez-vous : Product se sert de Details et Pricing pour pouvoir charger les données. La requête arrivera donc d'abord dans le service Product qui, lui, va dispatcher les requêtes sur les autres services concernés (Details et/ou Pricing) en fonction des paramètres de cette requête. Product doit donc pouvoir transmettre cette requête en fonction des données enregistrées par Eureka.
Spring intervient afin de pouvoir récupérer ces informations. Tout d'abord, l'objet RestTemplate est utilisé ici pour envoyer les requêtes aux autres services et nous le récupérons depuis le contexte Spring avec l'annotation @Autowired. Étant donné que nous ne connaissons pas la localisation physique des services, nous allons utiliser un autre objet tiré du contexte Spring : DiscoveryClient.
Voici un exemple de méthode permettant à Product de récupérer des informations depuis le service Details :
2.
3.
4.
5.
6.
7.
8.
9.
@Autowired
private RestTemplate rt;
@Autowired
private DiscoveryClient dc;
...
String url = dc.getNextServerFromEureka("details-service", false).getHomePageUrl();
return rt.getForObject(url, DetailsDTO.class);
La méthode getNextServerFromEureka() permet d'interroger Eureka sur la localisation du service, ici details-service (N.B. Le nom que nous lui avons donné grâce à l'attribut spring.application.name), et de récupérer son URL. Par la suite, nous utilisons RestTemplate et sa méthode getForObject() pour récupérer une liste d'objets DetailsDTO (que nous verrons plus tard).
En somme, Eureka, en combinaison avec Spring, permet de fournir l'adresse des services qui se sont connectés au serveur. Cela renforce donc ce principe d'indépendance et de faible couplage entre les services. Aussi, en nous permettant l'accès au DiscoveryClient, nous verrons qu'il sera possible de modifier la stratégie de load-balancing, en utilisant Ribbon (un IPC réalisé par Netflix), en répartissant la charge en fonction des instances d'un même service, par défaut.
Dans la prochaine section, nous allons nous pencher sur l'utilisation d'Apache Cassandra afin de pouvoir récupérer les informations qui permettent de peupler notre service Product. Puis nous parlerons aussi de Zuul, le point d'entrée de notre architecture, et surtout sa capacité à faire du dynamic filtering.
IV. Zuul, gatekeeper et filter loader depuis Cassandra▲
Désormais, nos services savent se retrouver et communiquer entre eux en passant par Eureka. Cet élément central de notre architecture étant mis en place, il s'agit de pouvoir contrôler les requêtes entrantes et d'utiliser tout le potentiel d'un tel reverse proxy, et plus encore.
IV-A. Zuul, mais pour quoi faire ?▲
Zuul est un service qualifiable de « point d'entrée » permettant de faire du proxy inverse au sein d'une application. Il se place donc en entrée de l'architecture et permet de réaliser des opérations avant de transmettre la requête aux services et sur leur retour. Zuul fait partie de la stack Netflix OSS et utilise en interne certaines autres applications de la stack, comme Ribbon et Hystrix, par exemple.
Si Zuul a été choisi parmi d'autres solutions capables de fournir la même panoplie de services, c'est parce que la solution de Netflix possède un argument de poids : il permet la gestion de filtres dynamiques, qui peuvent être stockés en base. Pour l'instant, seule la base de données NoSQL Cassandra est supportée, mais il est très simple d'implémenter un connecteur pour tout autre système de persistance. Cette fonctionnalité permet de modifier le comportement de Zuul vis-à-vis des requêtes au runtime, sans avoir à relancer le serveur. Les transactions opérées en base sont réalisées en utilisant Astyanax, un client Cassandra pour Java développé aussi par Netflix.
IV-B. Mise en place du serveur▲
Afin de configurer notre serveur Zuul, nous allons utiliser Spring Boot et Spring Cloud et les annotations qui ont été créées : @EnableZuulProxy et @EnableZuulServer. Ces annotations sont présentes dans le module spring-cloud-starter-zuul, et pour la partie chargement de filtres dynamiques, il faut utiliser le module Zuul de Netflix zuul-netflix. Voici à quoi ressemble le main d'un serveur Zuul :
2.
3.
4.
5.
6.
7.
8.
@EnableAutoConfiguration
@EnableZuulProxy
public class ZuulServerApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(ZuulServerApplication.class, args);
}
}
Il faut aussi le configurer en utilisant un fichier application.yml pour lui indiquer où se situe le serveur Eureka, et surtout, indiquer les routes à utiliser pour tel ou tel service. Le point d'entrée « fonctionnel » de notre application étant le service Product, il faut indiquer à Zuul quelle route utiliser pour requêter Product.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
server:
port: 8765
eureka:
client:
serviceUrl:
defaultZone: http://127.0.0.1:8761/eureka/
instance:
metadataMap:
instanceId: ${spring.application.name}:${spring.application.instance_id:${server.port}:${random.value}}
zuul:
routes:
product-service:
path: /products/**
serviceId: product-service
stripPrefix: false
Le serveur Zuul apparait désormais dans la liste des services inscrits dans le registre des services d'Eureka. Désormais, toute requête vers Product passera par Zuul en utilisant l'URL suivante : http://ip_de_zuul:port_de_zuul/products.
IV-C. Chargement dynamique des filtres▲
Maintenant que le serveur est en place, nous pouvons utiliser Astyanax pour nous connecter à notre base Cassandra, et ainsi prétendre à utiliser le système de chargement de filtres dynamiques. Nous aurions pu utiliser le driver Datastax, ce qui a été fait du côté des « sous-services » Details et Pricing pour requêter la base de données. Dans ce cas précis de filtres dynamiques, Netflix a préféré utiliser Astyanax. Voici comment se connecter à une base Cassandra et récupérer un Keyspace :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
public void connectToCassandra() {
LOG.info("Connecting to Cassandra database...");
ctx = new AstyanaxContext.Builder()
.forCluster(CLUSTER)
.forKeyspace(KEYSPACE)
.withConnectionPoolConfiguration(
new ConnectionPoolConfigurationImpl("productcpc")
.setSeeds(CASSANDRA_DB_IP)
.setPort(CASSANDRA_DB_PORT)
.setAuthenticationCredentials(
new SimpleAuthenticationCredentials(CASS_USER, CASS_PASSWORD))
.setMaxConnsPerHost(1))
.withAstyanaxConfiguration(
new AstyanaxConfigurationImpl()
.setDiscoveryType(NodeDiscoveryType.NONE)
.setCqlVersion(CQL_VERSION)
.setTargetCassandraVersion(CASSANDRA_VERSION))
.buildKeyspace(ThriftFamilyFactory.getInstance());
ctx.start();
LOG.info("Connected to Cassandra database " + CASSANDRA_DB_IP + ". Cluster : " + CLUSTER);
ks = ctx.getClient();
LOG.info("Keyspace : " + ks.getKeyspaceName());
}
Cet objet Keyspace va nous permettre d'utiliser ZuulFilterDAOCassandra. En combinaison avec ZuulFilterPoller, le mécanisme automatique de récupération des filtres en base sera lancé. Cependant, ces filtres ont une certaine particularité qui découle de leur dynamisme : ils doivent être écrits en Groovy. Aussi, ces filtres doivent hériter de la classe abstraite ZuulFilter et implémenter certaines méthodes qui décriront le comportement du filtre, par exemple : son ordre d'exécution, son type (pre, post ou route), etc.
2.
3.
dao = new ZuulFilterDAOCassandra(ks);
...
ZuulFilterPoller.start(dao);
Il est aussi possible de charger les filtres depuis le FileSystem, à défaut de vouloir utiliser une base de données.
Après avoir mis en place le chargement dynamique, il s'agit de créer son propre filtre pour un cas d'utilisation en particulier. Ces filtres peuvent être utilisés pour établir des règles de sécurité, de faire de l'A/B testing ou du canary testing, voire d'ajouter des paramètres à vos requêtes, dans un header par exemple. Les possibilités sont très nombreuses ce qui fait de Zuul un outil important et très pratique pour mieux gérer votre application.
La prochaine et dernière partie de ce REX se penchera sur l'utilisation d'Hystrix, application permettant de faire de la « fault tolerance », de son dashboard et de la stack ELK pour la concentration et l'analyse des logs.
V. Hystrix, son dashboard et la stack ELK▲
Notre registre de services (Eureka) est en place, ainsi que notre point d'entrée (Zuul) avec le chargement dynamique de filtres depuis Cassandra. Il reste un dernier point à aborder, assez important pour y consacrer une partie de ce REX : que faire lorsqu'un service ne fonctionne plus ? Comment le savoir ? Comment le prévenir ?
V-A. La solution Hystrix▲
V-A-1. « Fail fast, rapid recovery »▲
Les services sont amenés à arrêter de fonctionner à plusieurs reprises, du fait de leur répartition, ou encore du nombre trop important de requêtes. C'est un phénomène qualifiable de « récurrent » dans le domaine des microservices, ce qui a forcé les développeurs à créer un outil qui permettrait d'empêcher le blocage d'un service, d'adapter son comportement quand cela arrive, voire essayer de prévenir la faille.
Martin Fowler, dans son article au sujet des microservices (mentionné dans le premier article de notre série), nous parle de « détection des failles » et de « restauration des services ». Si le service doit s'arrêter, il faut qu'il s'arrête assez vite pour que l'on puisse y remédier tout aussi rapidement.
V-A-2. Les différentes fonctionnalités d'Hystrix▲
Conscient de cette problématique, les ingénieurs de Netflix (eh oui, encore eux !) ont décidé de partager leur solution de « fault tolerance » avec la communauté, en créant Hystrix, logiciel open source faisant partie de la stack Netflix OSS. Ce logiciel permet de faire s'arrêter rapidement un service qui ne peut plus fonctionner. Hystrix implémente aussi un système de « circuit breaker » qui permet de rompre le lien entre la requête et le service destiné à fonctionner, pour éviter des problèmes d'overload. En ouvrant le circuit, Hystrix va signaler à Eureka que le service ne peut plus fonctionner correctement, afin de rediriger les requêtes sur d'autres instances de ce service. Ce signalement se fait indirectement, car le service en question, étant en circuit ouvert, n'enverra plus de heartbeat à Eureka, qui va donc, purement et simplement, le retirer de son registre.
Hystrix propose aussi une solution de « fallback » afin de minimiser l'impact aux yeux de l'utilisateur. Ce fallback est représenté sous la forme d'une méthode qui sera déclenchée si le service ne répond pas, quelle qu'en soit la raison. Afin de pouvoir y prétendre, il faut créer une classe qui représentera la fonctionnalité du service en question, et qui devra hériter de la classe abstraite HystrixCommand.
Et afin d'améliorer l'expérience Hystrix, Netflix a aussi dévoilé un dashboard utilisé en combinaison avec Hystrix afin d'avoir des informations sur l'état de santé des commandes Hystrix en temps réel. Le dashboard est une application à part entière qu'il s'agira de lancer préalablement aux services. Récupérer le dépôt Git et lancer l'application suffisent pour pouvoir utiliser le dashboard.
Avant de créer ces classes et de pouvoir monitorer votre application, il faut annoter vos services avec @EnableHystrix et @EnableHystrixDashboard.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
<dependency>
<groupid>org.springframework.cloud</groupid>
<artifactid>spring-cloud-starter-hystrix-dashboard</artifactid>
</dependency>
<dependency>
<groupid>com.netflix.hystrix</groupid>
<artifactid>hystrix-javanica</artifactid>
<version>1.4.0-RC6</version>
</dependency>
<dependency>
<groupid>com.netflix.hystrix</groupid>
<artifactid>hystrix-core</artifactid>
<version>1.4.0</version>
</dependency>
2.
3.
4.
5.
6.
7.
8.
9.
10.
@SpringBootApplication
@EnableEurekaClient
@EnableHystrix
@EnableHystrixDashboard
public class ProductApplication {
public static void main(String[] args) {
SpringApplication.run(ProductApplication.class, args);
}
}
Maintenant que notre service est proprement annoté, voici comment créer vos classes représentant vos commandes Hystrix, dans les grandes lignes :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
public class GetDetailsCommand extends HystrixCommand<DetailsDTO> {
@Autowired
private RestTemplate rt;
@Autowired
private DiscoveryClient dc;
public GetDetailsCommand() {
super(HystrixCommand.Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("product"))
.andCommandKey(HystrixCommandKey.Factory.asKey(getDetails)));
}
@Override
protected DetailsDTO run() throws Exception {
String url = dc.getNextServerFromEureka("details-service", false).getHomePageUrl();
...
return rt.getForObject(url, DetailsDTO.class);
}
@Override
protected DetailsDTO getFallback() {
System.out.println("getDetails fallback.");
return null;
}
}
Cette méthode fallback permet d'imaginer bon nombre de solutions pour gérer ce cas de figure, comme retourner un résultat de requête précédent issu d'un cache, ou rediriger vers un autre service, etc. La structure étant assez implicite, les solutions sont multiples, c'est pourquoi aucun exemple n'est vraiment donné ici.
V-A-3. Le dashboard Hystrix▲
Maintenant que les commandes sont en place, vous pouvez lancer une instance d'Hystrix dashboard. En vous connectant à cette application, vous tomberez sur cette page d'accueil :
Il vous suffit désormais de renseigner l'URL de votre service utilisant les HystrixCommand mentionnées plus haut, en rajoutant /hystrix.stream à la fin. En cliquant sur Monitor Stream, vous tomberez sur une page similaire à celle-ci :
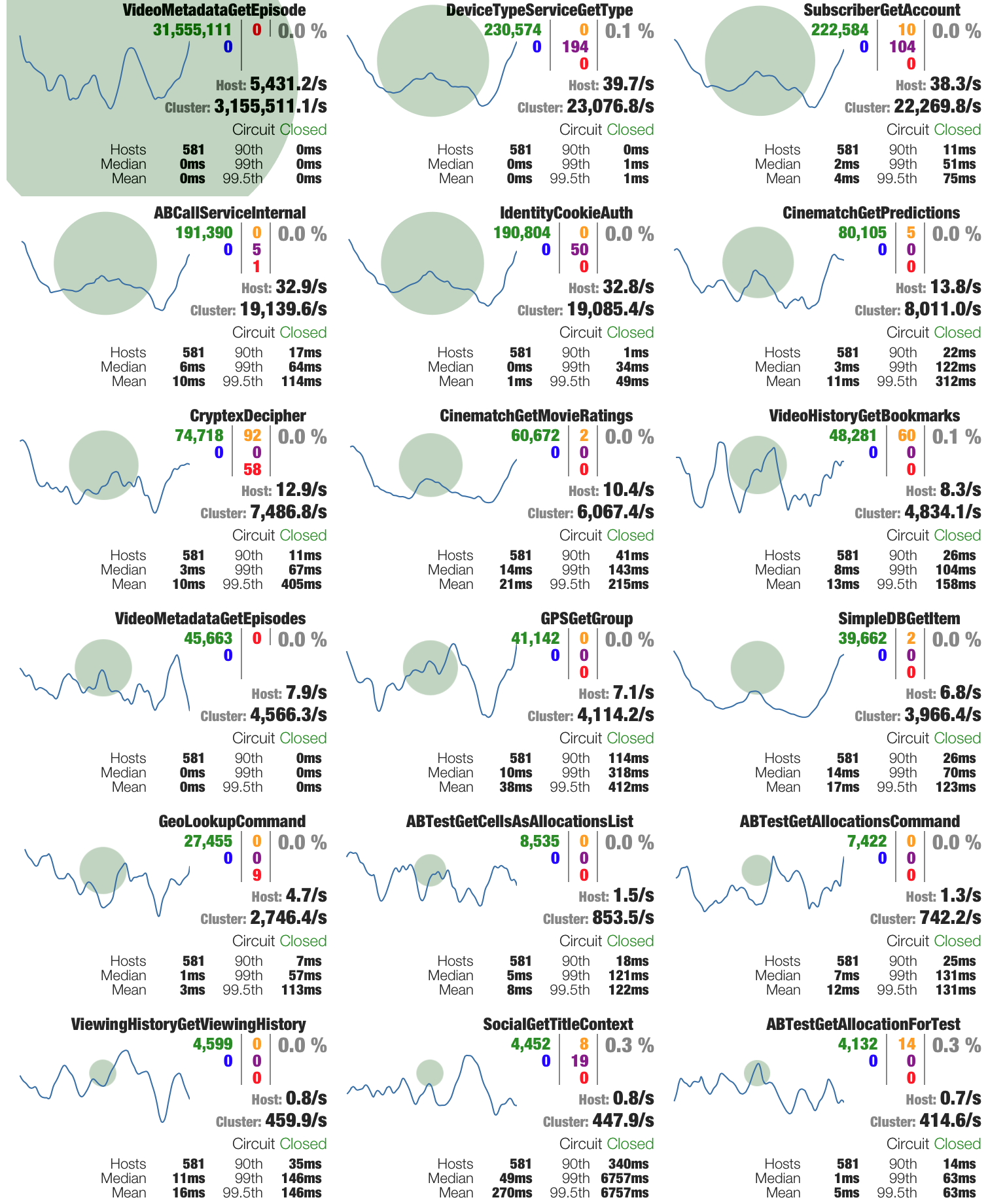
Vous voici devant votre dashboard représentant l'activité de vos commandes, donc de vos services, en temps réel. Retrouvez les explications concernant les différents indicateurs sur la page wiki du dashboard Hystrix.
V-B. Logging avec la pile Elasticsearch-Logstash-Kibana▲
Maintenant que tout est en place, et du fait de cette architecture fortement scalable, les services vont s'y multiplier à grande vitesse, et plusieurs instances d'un même service vont se créer. Cela va devenir très vite assez complexe comme environnement et il sera difficile de pouvoir suivre l'activité d'un service en particulier si jamais il venait à devenir défectueux. Rassembler les logs peut aussi permettre, dans une certaine mesure, de prévenir les dysfonctionnements et de repérer assez rapidement quel service ne fonctionne pas bien.
V-B-1. Depuis la console et les fichiers de logs…▲
Spring Boot génère déjà un certain nombre de logs qui peuvent s'avérer pratiques, depuis le lancement des multiples beans et de Tomcat jusqu'à certains logs liés aux requêtes entrantes, par exemple. Nous avons donc choisi de réutiliser ceux-là et d'y rajouter quelques informations :
- le PID de l'instance du service en question ;
- un UUID qui permettrait de suivre la requête depuis son entrée dans l'application, jusqu'à l'écran de l'utilisateur.
Ces informations sont donc intégrées dans les logs que nous avons choisi de stocker dans la machine où sont exécutés les services (machine locale ou VM) afin de les propager plus tard.
Pour pouvoir ajouter ces informations, nous avons utilisé Logback afin de pouvoir ajouter manuellement des éléments aux logs déjà existants. Nous récupérons donc le PID du service instancié pour l'intégrer aux logs.
Un UUID a été ajouté en utilisant Zuul via un filtre. Ce dernier va ajouter dans un header custom X-RequestID une valeur UUID random, et il sera possible de la récupérer dans chacun des services et de l'écrire dans les logs console et fichiers. Cette valeur permettra de suivre le parcours d'une requête dans les nombreux services qu'elle a traversés et détecter des problèmes, ou simplement vérifier que cela fonctionne bien.
Il faut savoir aussi que Kibana permet notamment de récupérer le hostname de la machine depuis laquelle les logs ont été récupérés, ce qui peut aussi servir pour retrouver un service en particulier.
V-B-2. … en passant par Logstash…▲
Après avoir stocké les logs dans des fichiers locaux à une machine, il faut pouvoir les envoyer vers une instance Elasticsearch. Ce dernier est un moteur de recherche libre et open source (comme ses camarades Logstash et Kibana) basé sur Lucene, bibliothèque de la fondation Apache. Elasticsearch ajoute une interface de type API Web (permettant par exemple l'indexation à partir de requêtes HTTP) à Lucene et assure les mécanismes d'indexation et de recherche de données.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
input {
file {
type => "java"
path => "/home/ubuntu/logs/*.log"
codec => multiline {
pattern => "^%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}.*"
negate => "true"
what => "previous"
}
}
}
...
output {
...
elasticsearch {
host => "10.0.40.13"
}
}
Logstash, par opposition à Elasticsearch, est lancé dans la même VM que celle contenant certains services. Ainsi, Logstash récupère les logs écrits localement par les services et Spring Boot, et les distribue à l'instance distante d'Elasticsearch. Une problématique pourrait se poser à grande échelle : Logstash a cet inconvénient d'être assez lourd comme processus, et placer une instance dans chaque VM, parmi des services potentiellement assez gourmands en ressources, peut rapidement devenir gênant. Mais c'est une autre histoire…
V-B-3. Vers le visualiseur de données Kibana▲
Maintenant que les logs sont stockés dans Elasticsearch, il est possible de les visionner, d'en faire des graphiques ou d'afficher certains logs plutôt que d'autres, en utilisant Kibana. Il s'agit là d'un outil très important, car il permet de mettre de l'ordre dans la multitude de données qui peuvent être utilisées.
Pour lancer une instance de Kibana, il suffit de télécharger le zip et d'ajouter l'URL d'Elasticsearch dans le fichier config/kibana.yml. En vous dirigeant ensuite sur l'interface graphique de Kibana (à l'adresse http://yourhost.com:5601), vous pouvez créer des graphiques en fonction de plusieurs données, notamment timestamp ou encore les différents hostname des machines. Voici à quoi ressemble un graphique dans Kibana :
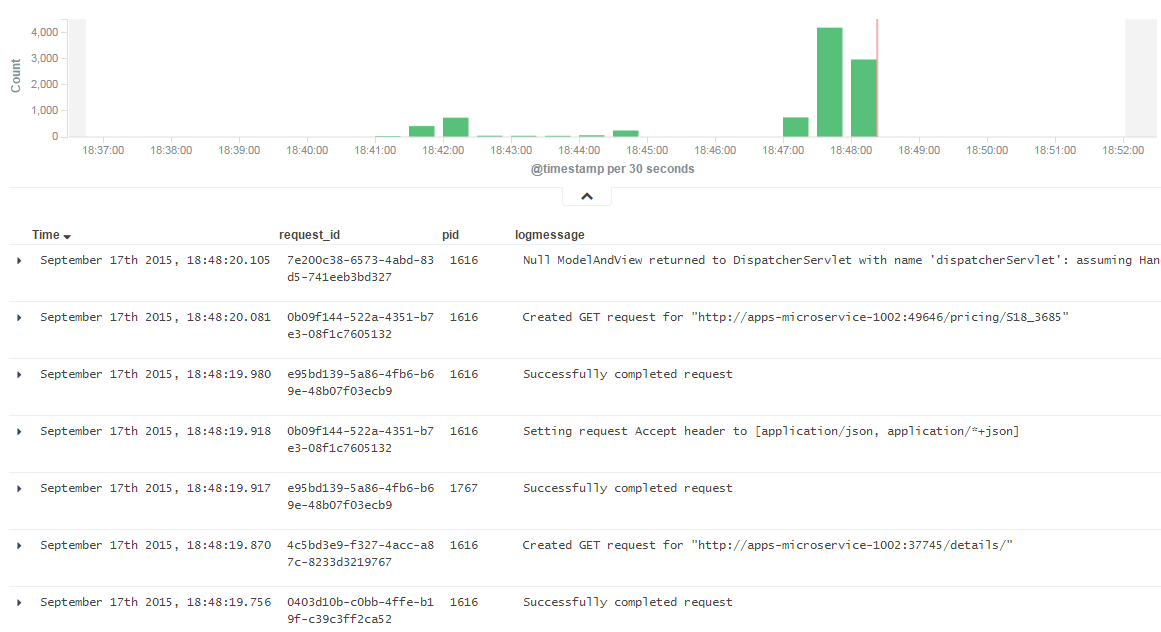
La combinaison de ces trois outils, ainsi que les logs Spring Boot et l'utilisation de Logback, les logs sont ainsi stockés et consultables par le biais d'une interface graphique.
VI. Conclusion▲
Nous venons de présenter un article qui présente un retour d'expérience sur la procédure de création d'une architecture orientée microservice de toutes pièces
VII. Remerciements▲
Cet article a été publié avec l'aimable autorisation de la société Ippon. L'article original peut être vu sur le blog/site de Ippon.
Nous tenons à remercier Claude Leloup pour la relecture orthographique de cet article et Mickael Baron pour la mise au format Developpez.com.