




I. Factures et commandes▲
I-A. Introduction▲

Aujourd'hui, je vous propose de voir le cas concret de la modélisation des factures ou des commandes dans Cassandra.
Ce premier exemple n'est pas choisi au hasard : c'est un cas concret très fréquent dans les applications de gestion. Il correspond à un cas d'école pour expliquer les jointures du SQL, mais aussi les documents de MongoDB. Nous verrons que contrairement à ce qu'on pourrait penser a priori, il se modélise très bien dans Cassandra à condition de bien comprendre le modèle CQL3.
I-B. Modèle conceptuel▲
Avant de partir dans la modélisation spécifique à Cassandra, prenons un instant pour construire un modèle conceptuel et dessinons-le sous la forme d'un diagramme UML.
Nous allons prendre le cas d'une facture, la commande étant identique à ceci près qu'il y a écrit « commande » au lieu de « facture » sur l'entête. Une facture est un document composé principalement de deux parties :
-
Un entête (invoice) qui contient toutes les informations générales :
- un identifiant de la facture ;
- la date de la facture ;
-
les informations sur le client ;
- nom,
- adresse ;
- la date de paiement ;
- le montant total de la facture ;
- …
-
Une liste de lignes de facturation (invoice item) qui détaille l'ensemble des objets et des prestations facturées. Chaque ligne contient des informations comme :
- un identifiant de la ligne ;
- la description de l'objet ou la prestation facturée ;
- la quantité facturée ;
- le prix unitaire ;
- éventuellement le total de la ligne ;
- …
Une ligne de facturation n'existe que dans le cadre d'une facture donnée. Il s'agit dont d'une relation de composition.
La facture est généralement liée à l'entité du client (client) facturé. Les lignes sont, elles, liées au produit vendu. Cependant, une facture n'étant pas modifiable, toutes les données modifiables de ces entités sont copiées pour garantir la validité des données.
Nous obtenons le diagramme suivant :

I-C. Le modèle de données de Cassandra▲
Avant de nous lancer dans la modélisation de notre facture dans Cassandra, il est important de bien comprendre le modèle de la base. J'imagine, Ô lecteur, que tu sais que Cassandra est une base de données de type famille de colonnes. Pourtant, avec l'arrivée de CQL3, le modèle logique de la base a complètement changé. Et l'ancien modèle de Map<SortedMap> inspiré de Google Big Table est sur le point de disparaitre.
Actuellement, Cassandra est une base de données que je qualifierais de tabulaire partitionnée. Les données sont organisées en tables, dont les colonnes et leurs types sont définis par un schéma. Chaque ligne est identifiée par une clé primaire. Les lignes peuvent être regroupées dans une partition. Une partition est identifiée par une clé de partition qui est un préfixe de la clé primaire de la table. Cassandra garantit que toutes les lignes d'une partition sont stockées ensemble. De plus, elles sont classées par l'ordre lexicographique des colonnes de la clé primaire qui ne font pas partie de la clé de partition. Ces colonnes importantes sont appelées « clustering columns ». Grâce à cela, il est possible de demander toutes les lignes d'une partition à la fois ou de demander une tranche de lignes en ne précisant les valeurs que d'un préfixe de la clé primaire ou une inégalité sur la dernière clustering column.
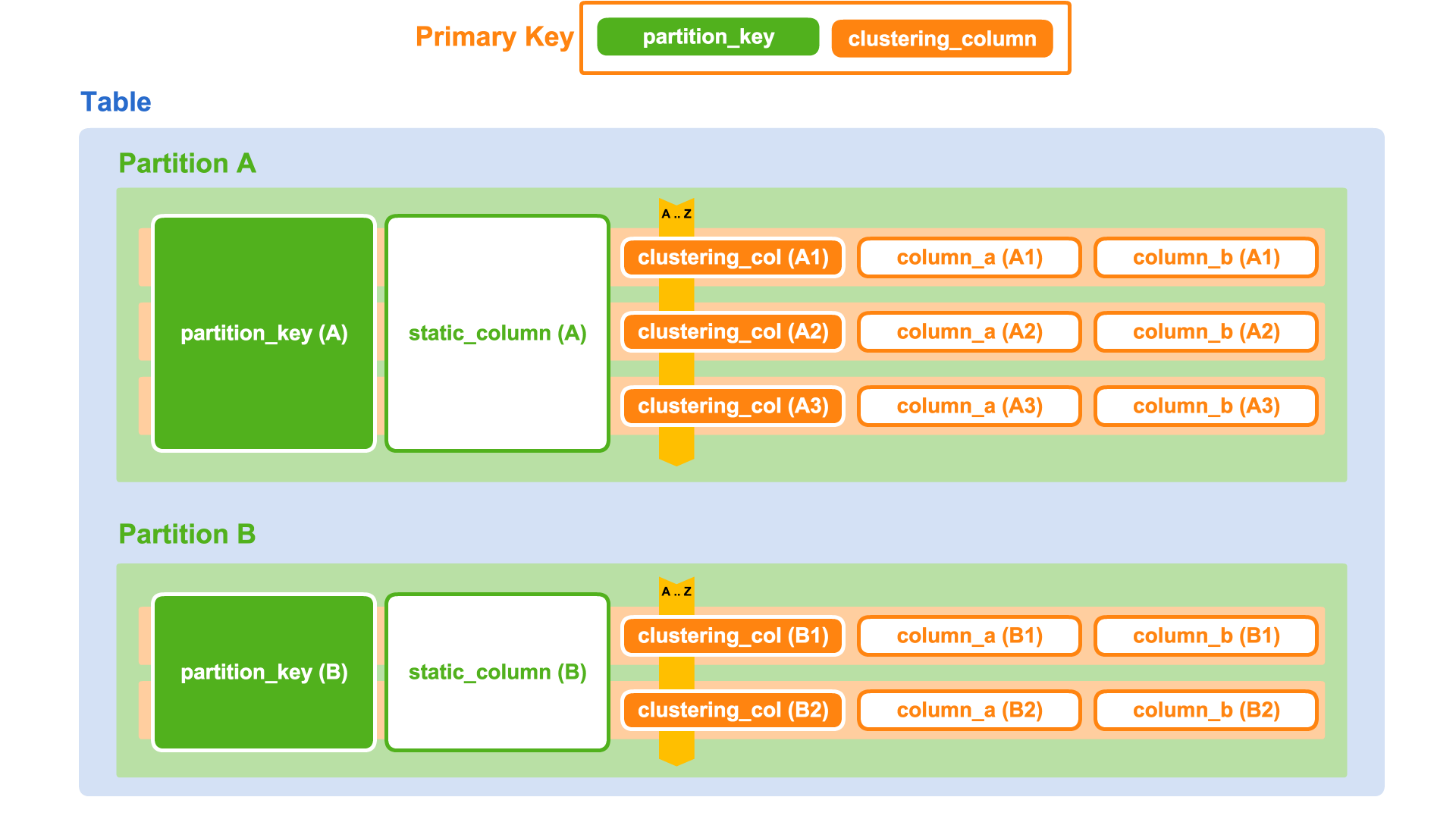
Une partition peut posséder des colonnes qui lui sont propres. Qualifiées de statiques, elles ne sont stockées qu'une fois par partition et possèdent la même valeur pour toutes les lignes de cette dernière. Le mot-clé static utilisé dans la définition a été pris du mot-clé en Java qui permet de partager une valeur entre toutes les instances d'une même classe.
I-D. Modèle logique▲
Après ce petit détour théorique, voyons comment modéliser notre facture dans Cassandra.
En général, lorsqu'on modélise une base Cassandra, on recense toutes les requêtes en lecture qu'on veut pouvoir exprimer et on construit les tables qui répondent à ce besoin. Les requêtes auxquelles nous voudrons répondre ici sont :
- Lister les factures d'un client du plus récent au plus ancien. Seul un résumé de la facture devra être affiché ;
- Charger le détail d'une facture à partir de l'identifiant de facture trouvé grâce à la première requête.
À partir de ces requêtes, nous allons construire un diagramme de Chebotko. Ce dernier permet de réfléchir à la modélisation des tables Cassandra. Il doit son nom au premier auteur de la formation à la modélisation de Cassandra qui n'a pas trouvé mieux pour se faire connaître que de donner son nom à ces diagrammes.
I-D-1. Lister les factures du client▲
Pour répondre à la première requête, nous allons lister un résumé de la facture de chaque client. Notre clé de recherche est l'identifiant du client, elle prendra naturellement la place de clé de partition. Les informations spécifiques au client, mais indépendantes de la facture comme son nom et son prénom, seront copiées dans des colonnes statiques pour éviter une jointure trop coûteuse lorsqu'on travaille avec Cassandra. Chaque résumé de facture sera enregistré dans une ligne.
Les dernières factures étant les plus intéressantes, nous classerons les factures dans l'ordre descendant.
À cette étape, nous obtenons le schéma suivant :
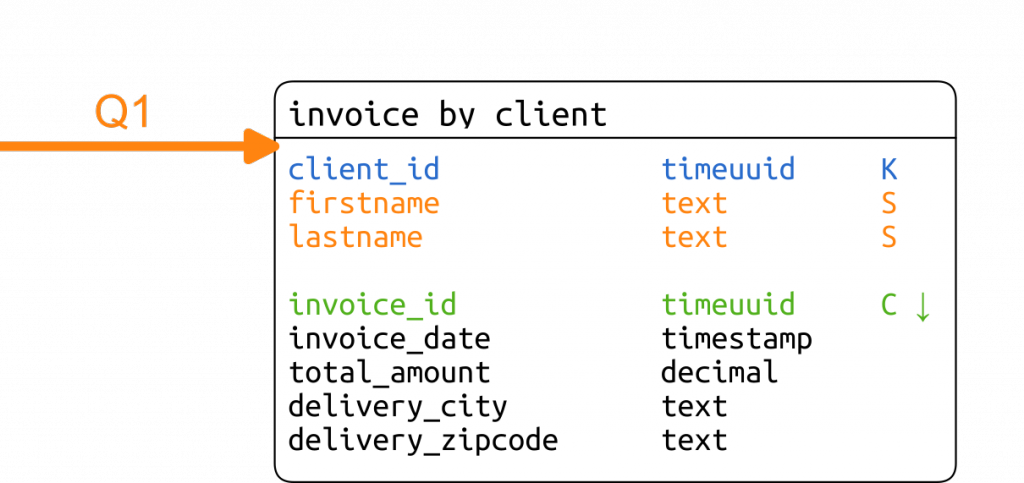
La liste des factures du client obtenue, elle sera présentée à l'utilisateur d'une manière ou d'une autre. Celui-ci sera à même de choisir un élément dans la liste et d'en demander le détail.
I-D-2. Charger le détail d'une facture▲
Pour stocker le détail d'une facture, nous allons nous appuyer sur la relation de composition entre les entités Invoice et InvoiceItem. Celle-ci se traduit naturellement dans le modèle Cassandra par l'imbrication des lignes dans une partition. La partition et les colonnes statiques représentent l'entité contenante, Invoice dans notre cas, et les lignes l'entité contenue, ici InvoiceItem.
Les données utiles décrivant le produit et le client sont copiées dans les lignes et partitions.
Lors de cette modélisation, nous mettons en forme deux mécanismes importants : la duplication et l'imbrication. La duplication est mise en œuvre quand les données du client ou du produit sont copiées dans la table invoice. L'imbrication est mise en œuvre lorsque les lignes de factures sont incluses dans la partition qui représente la facture.
Il est important de distinguer la duplication technique du nom du client, qui est une forme de dénormalisation motivée par les performances applicatives, et la copie fonctionnelle de l'adresse qui fait partie du modèle conceptuel et répond à un besoin métier.
La table invoice ainsi produite ressemble fortement à la table invoice_by_client. Elles diffèrent cependant dans l'interprétation d'un même élément. La table invoice représente deux entités imbriquées. Elle est la source de vérité des données qui y sont conservées à l'exception des champs copiés depuis Client et Produit. La table invoice_by_client représente une relation 1-* : seuls les identifiants y sont significatifs, les autres données ne sont que des copies de dénormalisation.
À la fin, on obtient le diagramme suivant :

I-E. Modèle physique▲
Le modèle logique obtenu, il est d'usage de le transformer en modèle physique.
Cela consiste en général à dégrader le modèle logique pour qu'il puisse fonctionner avec les vraies contraintes opérationnelles. Dans le cadre de Cassandra, il convient de vérifier que la taille d'une partition ne devient jamais trop grosse. Il est souhaitable de limiter une partition à 100 000 valeurs et 100 Mo pour éviter qu'une partition trop lourde ne plombe les performances.
Ici, le nombre de partitions de la facture ne risque pas de déborder. Il nous faut vérifier qu'il n'existe pas de superclient qui dispose d'un nombre de factures gigantesque. Nous supposerons ici que ce n'est pas le cas. Nous verrons dans un prochain article comment adapter le modèle pour éviter les partitions de très grande taille.
Il ne nous reste plus qu'à produire nos scripts CQL de création de tables.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
create keyspace invoice WITH replication = {'class': 'SimpleStrategy', 'replication_factor': 1 };
use invoice;
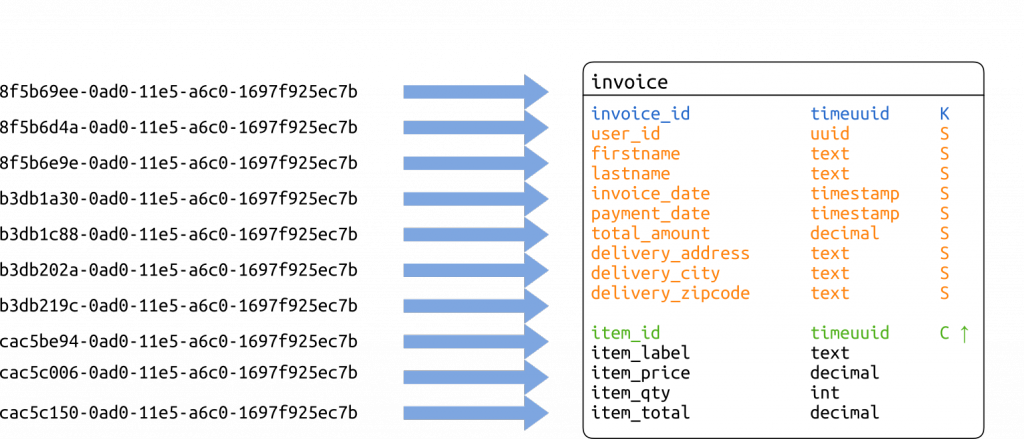
create table invoice (
invoice_id timeuuid,
firstname text static,
lastname text static,
invoice_date timestamp static,
payment_date timestamp static,
total_amount decimal static,
delivery_address text static,
delivery_city text static,
delivery_zipcode text static,
item_id timeuuid,
item_label text,
item_price decimal,
item_qty int,
item_total decimal,
primary key (invoice_id, item_id)
);
create table invoice_by_client (
client_id timeuuid,
firstname text static,
lastname text static,
invoice_id timeuuid,
invoice_date timestamp,
total_amount decimal,
delivery_city text,
delivery_zipcode text,
primary key (client_id, invoice_id)
)
with clustering order by (invoice_id desc);
Et maintenant, il ne reste plus qu'à développer notre superbe application…
II. Modélisation Cassandra : Recherche multicritère▲
Nous avons vu dans un premier article comment modéliser une facture. Dans ce contexte, nous pouvions rechercher les factures associées à un client. Il arrive cependant qu'on souhaite rechercher les données via d'autres critères, voire selon une combinaison de critères possibles. C'est la fameuse recherche multicritère classique dans les applications traditionnelles. Si elle a tendance à disparaître pour des recherches simplifiées, elle possède ses avantages et est parfois demandée avec insistance par le client. Nous allons voir maintenant comment résoudre le problème.

Les modélisations présentées dans cet article ont été réalisées par des professionnels.
N'essayez en aucun cas de les reproduire vous-même !
La recherche multicritère est un antipattern de Cassandra, sa mise en œuvre doit être réalisée avec la plus grande attention.
II-A. Modèle conceptuel▲
Pour cet article, nous reprendrons le modèle de la gestion de factures que nous modifierons un peu. Maintenant, notre application de facturation est fournie en mode SaaS hébergée par nos soins via la meilleure solution cloud du marché qui nous permet d'avoir une immense base de données qui contient toutes les données de tous nos utilisateurs.
Nous introduisons donc la notion d'utilisateur de l'application. Toutes les données sont maintenant cloisonnées par utilisateur. Notre modèle conceptuel est donc le suivant :
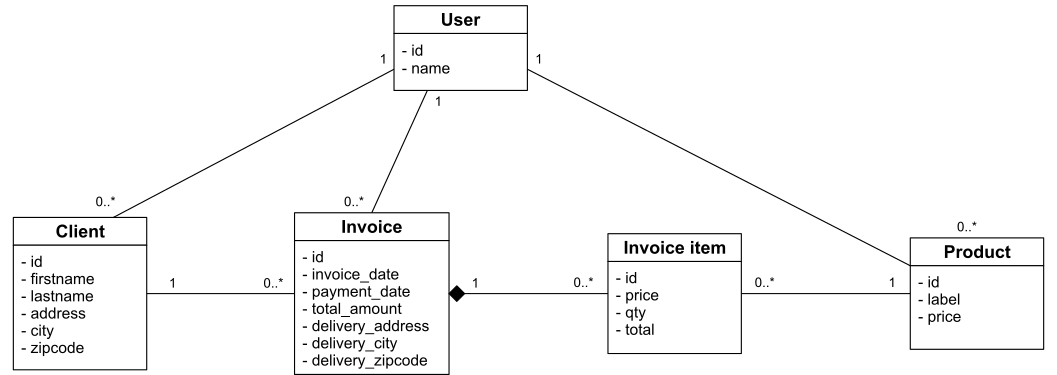
L'ajout de l'entité utilisateur parait anecdotique, mais c'est un prérequis indispensable au bon fonctionnement de la recherche multicritère.
II-B. Modèle logique▲
Comme nous l'avons fait lors de la modélisation des factures, nous créons une seule table qui imbrique l'entité InvoiceItem dans une partition représentant une entité Invoice.
Conformément à la modélisation classique d'une relation de composition 1-n.
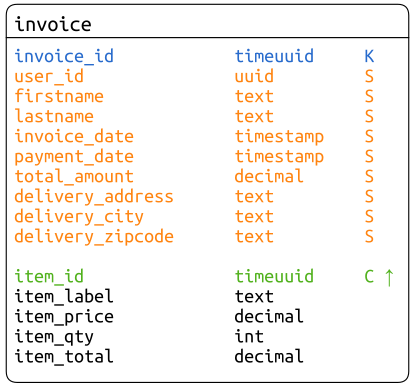
II-C. Recherche multicritère▲
Nous voulons pouvoir effectuer une recherche multicritère avec les caractéristiques suivantes.
Deux critères sont obligatoires :
- l'utilisateur est un critère implicite qui n'a pas à être saisi, puisque chacun ne peut chercher que dans ses données ;
- la date de facturation, sous la forme d'une plage de dates, début et fin.
S'ajoutent ensuite des critères facultatifs :
- le nom du client ;
- le prénom du client ;
- la ville de livraison ;
- le code postal de livraison.
La recherche est paginée. Les factures sont présentées dans l'ordre antéchronologique.
Pour un tel cas d'usage, la solution la plus évidente est de coupler un moteur de recherche avec notre base. Nous pourrions ainsi déployer un cluster Elasticsearch ou Solr et y indexer nos factures à la création. Cette solution est la meilleure en termes de fonctionnalité, mais reste complexe. Nous devons créer et maintenir un deuxième cluster et nous assurer que les données qu'il contient sont cohérentes avec celles de Cassandra. Et ce n'est pas aussi simple qu'on peut le croire, surtout avec une base gigantesque telle que le produit notre application SaaS.
Ici, nos besoins étant limités à des recherches simples et exactes, nous ne souhaitons pas ajouter cette complexité.
Les experts qui me liront diront que, comme nous avons une base installée importante, nous avons pris du support auprès de DataStax et que, dans la distribution DataStax Entreprise (DSE), il y a une version de Solr prête à l'emploi et totalement intégrée. Nous pouvons ainsi bénéficier des avantages d'un moteur de recherche documentaire en ne gérant qu'un cluster, la cohérence entre les tables et l'index étant, de plus, garantie par DSE.
Tout ceci est parfaitement vrai, mais ne pourrait nous suffire. En effet, si vous avez bien remarqué les critères de recherche, nous ne cherchons que sur des colonnes statiques, or l'intégration de Solr ne les gère pas à ce jour. De plus, nous cherchons des partitions (des factures) alors que ladite recherche Solr nous retourne des lignes. L'intégration Solr ne nous est donc d'aucune aide pour l'instant.
On pourrait penser aux index secondaires. Mais d'une part, on ne peut en utiliser qu'un à la fois et, d'autre part les index secondaires de Cassandra sont tellement particuliers qu'il vaut mieux les fuir.
II-D. Table d'index▲
Le mieux est de se rapprocher du fonctionnement des index inversés. Pour cela nous allons créer une table d'index pour chaque critère secondaire. Une table d'index ne contient pas d'autres données que sa clé primaire. La clé de partition contient l'identifiant de l'utilisateur, la date de facturation (sans les heures), le critère secondaire. La clé primaire se termine par l'identifiant de la facture comme unique clustering column classée dans l'ordre décroissant pour que les factures les plus récentes soient présentées en premier.
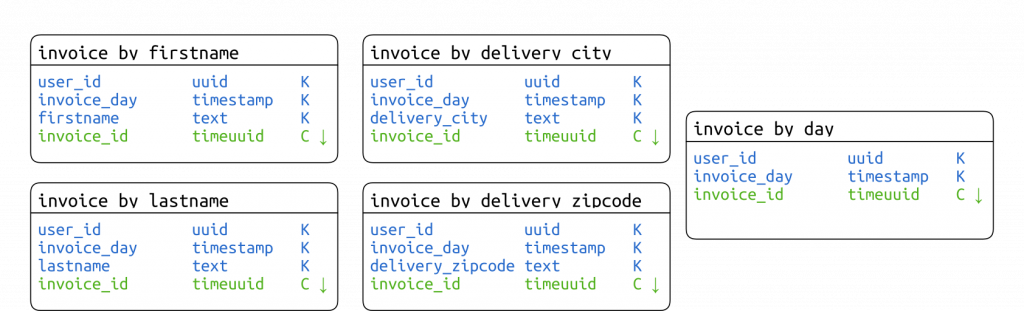
Notez que jusqu'à la version 2.1 de Cassandra, il faut gérer soi-même le contenu de la table, écrivant dans l'index en même temps. Cette gestion est facilitée parce qu'une facture n'est en principe jamais modifiée, tout changement donnant lieu à l'édition d'une nouvelle facture qui annule la précédente.
À partir de la version 3.0, nous bénéficions des vues matérialisées. Il suffit de la créer avec la commande suivante pour que Cassandra prenne en charge la dénormalisation des données.
2.
3.
4.
5.
6.
7.
8.
-- A partir de Cassandra 3.0
CREATE MATERIALIZED VIEW invoice_by_firstname
AS
SELECT invoice_id
FROM invoice
WHERE firstname IS NOT NULL
PRIMARY KEY ((user_id, invoice_day, firstname), invoice_id)
WITH CLUSTERING ORDER BY (invoice_id DESC)
II-E. Chercher dans les index▲
La recherche proprement dite s'effectuera simplement :
Pour une journée donnée et pour chaque critère de recherche renseigné, on effectue une recherche sur l'index correspondant au critère. Toutes les recherches sont envoyées en parallèle grâce à l'API asynchrone du driver Cassandra. Comme les résultats sont classés dans l'ordre décroissant, l'intersection des résultats est effectuée simplement en parcourant les resultSets en parallèle en ne conservant que les valeurs présentes dans tous. On s'arrête dès qu'on a assez de résultats pour remplir la page ou qu'un des resultSets est vide.
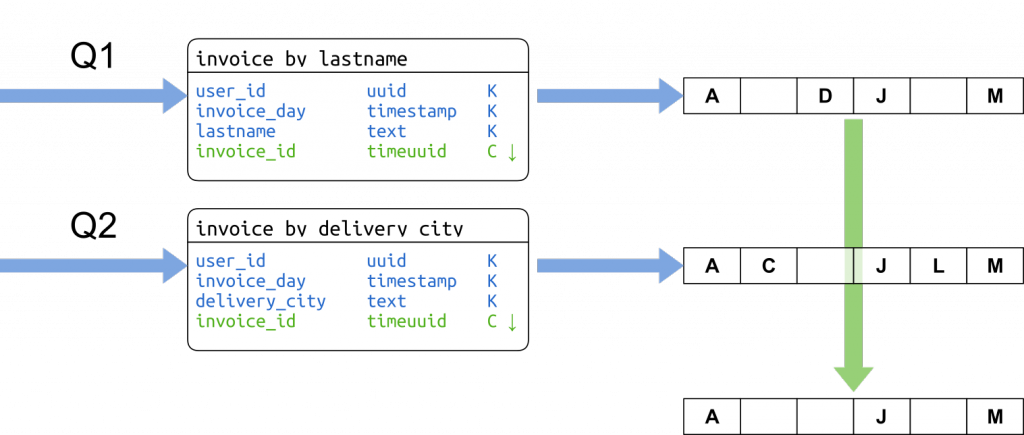
Si la première journée ne suffit pas à remplir une page de résultat, on recommence la journée précédente jusqu'à atteindre le début de la plage demandée.
La combinaison de la pagination des résultats, de la lecture paresseuse des resultSets et du classement cohérent des identifiants, permet à la fois d'économiser la mémoire de travail et de ne transférer vers le client que les données nécessaires. La mémoire nécessaire pour traiter une requête est bornée par la mémoire nécessaire pour stocker une page de résultat et les tampons des resultSets.
Une fois qu'on a obtenu une page d'identifiants, il suffit de charger toutes les factures à partir de leur identifiant. Dans ce cas, il est préférable de lancer toutes les requêtes - une par identifiant - en parallèle et de regrouper les résultats. Comme cela, on répartit les requêtes sur tous les nœuds du cluster. L'erreur serait de lancer une seule requête avec une clause where ... in (..., ...) qui charge un seul nœud coordinateur.
En Java 8, le code de réconciliation s'écrit simplement comme ceci :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
private int loadInvoices(List<Invoice> resultList, Iterator<UUID> uuidIt, int limit) {
List<CompletableFuture<Invoice>> futureList = new ArrayList<>(limit);
for (int i = 0; i < limit && uuidIt.hasNext(); ++i) {
futureList.add(invoiceRepository.findOne(uuidIt.next()));
}
futureList.stream()
.map(CompletableFuture::join)
.forEach(resultList::add);
return futureList.size();
}
Cette méthode charge les factures d'une journée dans la liste de résultats passée en argument dans la limite de limit documents.
Le deuxième argument, uuidIt, est l'itérateur qui correspond à l'intersection des lectures d'index qui est ici consommé de façon paresseuse.
II-F. Complexité▲
Tout comme nous avons limité l'empreinte mémoire utilisée, il est important de vérifier que le nombre de requêtes est maîtrisé. Un nombre de requêtes trop important risquerait de surcharger le cluster et ralentir les performances de façon générale.
Ici, nous effectuons au maximum une requête d'index pour chaque journée dans la plage de dates et pour chaque critère secondaire renseigné. Chacune de ces requêtes est de complexité partition by query qui correspond à la complexité minimale pour une requête Cassandra. À ceci s'ajoute une requête par élément trouvé dans la limite du nombre d'éléments dans la page.
Ainsi, si nous avons une requête avec trois critères, une plage de sept jours et une page de 100, le nombre de requêtes est inférieur ou égal à 121 ![]() .
.
Il suffit de borner la largeur possible de l'intervalle des dates et la taille des pages pour borner le nombre de requêtes et assurer que la complexité de la recherche est de type partition by query. C'est moins rapide qu'une requête unitaire, mais ça reste scalable. Sur le terrain, on obtient de très bonnes performances avec 5000 utilisateurs simultanés et 99 % des temps de réponse sous la centaine de millisecondes avec un seul serveur frontal et un cluster de cinq nœuds Cassandra.
Autrement dit, si Cassandra n'est pas faite pour la recherche multicritère, il est possible, dans certains cas, de lever cette limitation et de la faire fonctionner correctement.
II-G. Pour aller plus loin▲
Le sujet sera exposé au Cassandra Summit du 22 au 24 septembre 2015. En plus de la modélisation, vous y découvrirez l'implantation complète de la solution qui représente un bel exemple d'utilisation du driver Cassandra avec Java 8.
Ceux qui ne pourront se déplacer à Santa Clara pourront venir chez Ippon pour un IppEvent qui reprend l'exposé le 10 septembre ou faire intervenir l'auteur chez vous lors d'un Brown Bag Lunch.
III. Modélisation Cassandra : Gestion de panier▲
Continuons dans notre série d'articles sur la modélisation Cassandra (lire Factures et commandes et Recherche multicritère). Avant de pouvoir passer une commande et plus encore de produire une facture, votre client va devoir lister les articles qu'il souhaite acheter. Pour cela, l'application propose généralement d'utiliser un panier, liste remplie au fur et à mesure par l'utilisateur. C'est de cet objet particulier et important que nous allons parler aujourd'hui.
III-A. Panier▲
Les paniers ne se limitent pas aux sites marchands. On les retrouve dans la plupart des applications où les utilisateurs sont conduits à faire une sélection de plusieurs éléments, sur lesquels ils effectuent une opération en masse par la suite. Ce peut être une liste d'articles qui seront achetés en fin de navigation. Dans un logiciel de facturation, ce pourrait être une sélection de factures sur lesquelles on veut envoyer une relance. On peut aussi penser aux listes de préférences ou aux listes de souhaits.
Dans sa forme classique, un panier est donc une liste qui est remplie progressivement par ajout et retrait d'éléments. Souvent, le contenu sera exploité par une action qui provoquera son vidage.
Les éléments d'un panier ne sont pas classés. Il est fréquent que l'affichage classe les éléments, éventuellement triés par catégorie. Le classement et le tri sont des règles d'affichage qui sont réalisées par le tiers de présentation.
Par ailleurs, un panier doit pouvoir être manipulé de façon concurrente. On imagine souvent une personne seule devant son ordinateur en train de sélectionner deux livres, l'un après l'autre, puis de les commander. Mais ce n'est pas le seul cas d'usage. Vous rencontrerez aussi le cas d'un couple qui effectue ses courses en ligne chacun avec son ordinateur connecté sur le même compte. Madame réduit le nombre de packs de bières à un, parce que cinq c'est trop. Pendant ce temps, Monsieur en rajoute, parce qu'il en faut au moins trois pour la soirée foot de vendredi soir avec les copains. Les deux appuyant simultanément, l'un sur le bouton [+], l'autre sur le bouton [-]. À partir du moment où l'on travaille sur le web, il faut partir du principe que les requêtes vont s'exécuter en parallèle.
III-B. Modèle fonctionnel▲
Le modèle fonctionnel du panier est donc simple : c'est un sac, c'est-à-dire un ensemble qui peut contenir plusieurs fois le même élément. Le nombre de répétitions de l'élément étant conservé. Pour traiter le cas général, nos paniers seront nommés pour être distingués entre eux.
Le modèle conceptuel est donc le suivant :
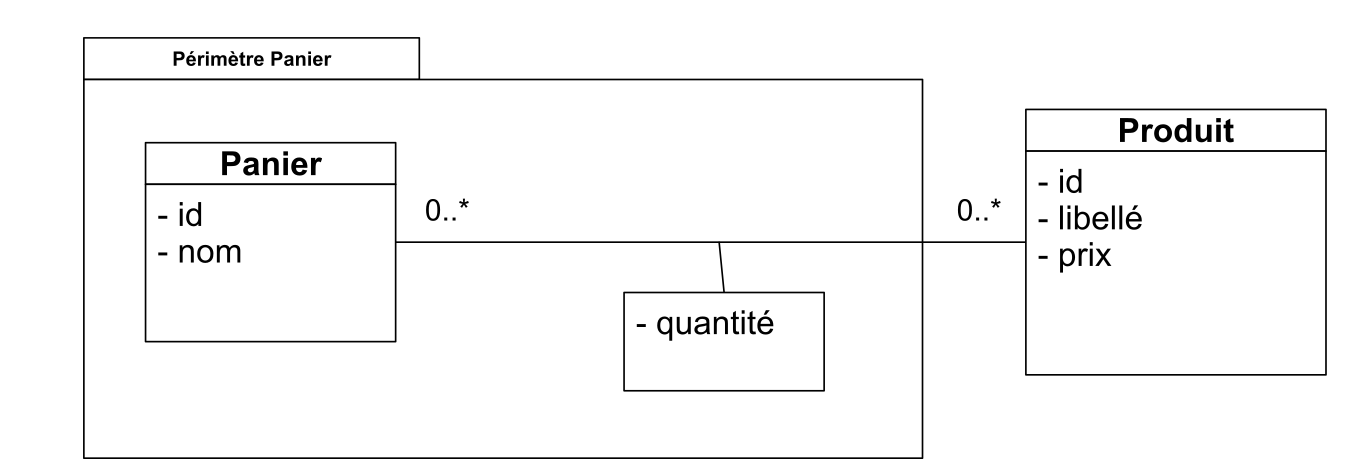
III-C. Modèle logique▲
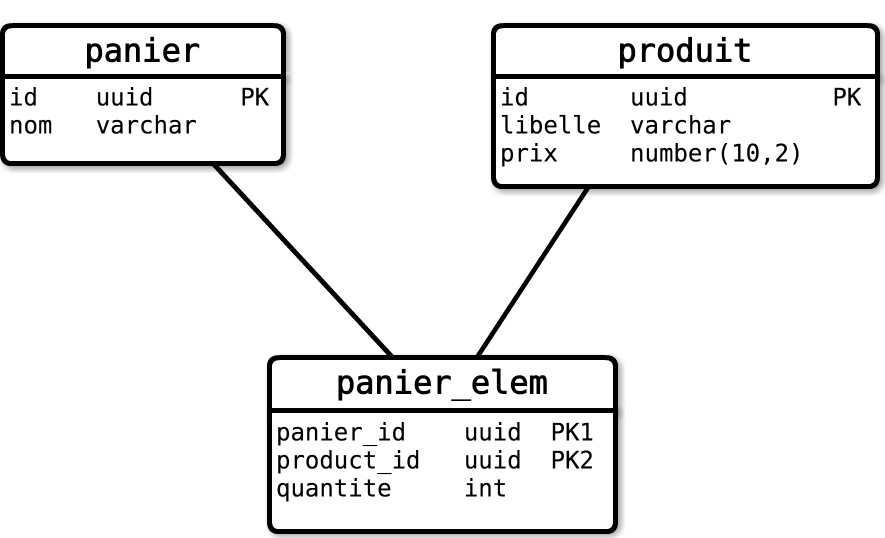
Avec une base relationnelle, le modèle de base se décline très simplement par l'utilisation de deux tables : l'une représente l'entité panier et l'autre la jointure N-N entre les entités Panier et Produit. La modélisation de l'entité Produit ne sera pas traitée ici. On simplifiera le propos en considérant qu'il est représenté par une table unique.
On obtient le schéma suivant :
III-D. Modèle naïf▲
Prenons le cas de Dave Lopernahif. Il connaît bien les bases de données relationnelles avec lesquelles il travaille régulièrement. Il utilise Cassandra depuis peu de temps, mais pense en avoir compris le fonctionnement. D'ailleurs, le modèle n'est-il pas proche ? Cassandra stocke les données dans des tables et CQL ressemble à s'y méprendre à SQL. Bien sûr, il faut s'adapter aux spécificités de la base et à l'absence de jointure. C'est pourquoi Dave sait qu'il doit stocker toutes les informations concernant le panier et sa jointure avec les produits dans une seule table. Heureusement, il a déjà lu un excellent article sur la modélisation Java où une relation de composition 1-N était modélisée grâce au mécanisme de partition. Ici, la relation n'est pas une relation de composition, les lignes ne représenteront pas l'entité Produit, mais le lien vers l'entité.
En suivant ce principe, Dave modélise sa table ainsi :
- la clé de partition est l'identifiant du panier ;
- le nom du panier est contenu dans une colonne statique (attribut de la partition) ;
- l'identifiant du produit est utilisé comme l'unique colonne de clustering ;
- la quantité est une colonne normale ;
- le libellé du produit et son prix peuvent être dénormalisés sous la forme de colonnes normales.
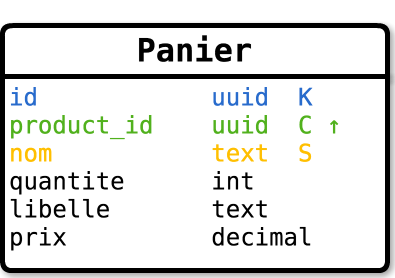
III-D-1. Modélisation naïve▲
Ainsi, nous garantissons l'unicité de la présence d'un produit, la gestion du nom du panier, du nombre d'éléments et les dénormalisations utiles.
Pour lire le contenu du panier, une requête suffit :
2.
3.
select *
from panier
where id = ?
Et notre développeur est content. Sauf que …
III-D-2. Gestion de la concurrence▲
Sauf que maintenant, il faut pouvoir gérer les modifications concurrentes. Et nous tombons dans le cas classique d'une modification par lecture puis écriture de la valeur modifiée.
Lors de l'utilisation d'une base de données relationnelle, la solution consiste à poser un verrou à la lecture puis à faire la modification. Le cas particulier de la première insertion devant être prise en compte. Or Cassandra ne permet pas de poser de verrou. « Mais, se dit Dave, il y a les transactions légères qui fonctionnent comme un compare-n-swap au niveau de la ligne‑». Il suffit donc pour lui de suivre l'algorithme suivant :
2.
3.
4.
select quantite
from panier
where id = :panier_id
and product_id = :product_id
Si on a un résultat, alors on définit : nv_quantite ← anc_quantite + quantite_ajoute et on exécute la commande suivante :
2.
3.
4.
5.
update panier
set quantite = :nv_quantite
where id = :panier_id
and product_id = :product_id
if quantite = :anc_quantite
Sinon on exécute :
2.
3.
insert (id, product_id, quantite, libelle, prix)
values (:id, :product_id, :quantite_ajoute, :libelle, :prix)
if not exists
Dans les deux cas, la deuxième commande peut échouer en cas de modification parallèle. Dans ce cas, on recommence à la première étape.
Avec ce fonctionnement, Dave Lopernahif obtient rapidement une application qui fonctionne.
III-D-3. Une modélisation efficace▲
Cependant, la modélisation de notre ami a deux problèmes importants :
- L'utilisation des transactions légères est lente. Elle est même très lente, car elle requiert quatre échanges entre le nœud coordinateur de la requête et les répliques ;
- De plus, le niveau de cohérence est de type SERIAL, qui est une cohérence immédiate forte et ne permet pas de bénéficier de la cohérence à terme offerte par Cassandra. Il en résulte une réduction de la haute disponibilité.
Cette modélisation n'est donc pas satisfaisante et il nous faut revoir complètement la modélisation.
On pourrait vouloir utiliser les compteurs. Seulement, une table contenant des colonnes de type compteur ne peut pas contenir de colonne d'un autre type, ce qui complique le modèle. Mais aussi, les requêtes d'augmentation et de réduction du compteur ne sont pas idempotentes, ce qui les rend peu fiables et limite leur utilisation à des comptages statistiques où un certain taux d'erreur est autorisé.
Pour obtenir une représentation efficace, il faut se souvenir que Cassandra est très fort pour ajouter des données et moins pour les modifier. Ainsi, plutôt que de stocker le contenu de la liste, il est préférable de stocker les évènements qui la modifient. Chaque évènement est identifié par un identifiant unique UUID de type 1, c'est-à-dire horodaté.
Notre table sera donc structurée ainsi :
- la clé de partition est l'identifiant du panier ;
- le nom du panier est contenu dans une colonne statique (attribut de la partition) ;
- l'identifiant de l'évènement constitue l'unique colonne de clustering classé par ordre croissant ;
- les données de l'évènement (product_id, quantité et valeurs dénormalisées) sont stockées comme des colonnes ordinaires.

Lors de la lecture, les évènements sont lus dans l'ordre chronologique et le panier est reconstitué par application successive des effets. Il n'y a ici qu'un type d'évènement qui correspond à une variation de la quantité qui peut être positive (ajout dans le panier) ou négative (retrait). Il faudra juste penser à retirer du panier final les articles dont la quantité est inférieure ou égale à zéro.
Cette modélisation a l'avantage de ne nécessiter que des ajouts de données, de gérer naturellement la concurrence et de ne nécessiter aucune lecture avant l'écriture. On est dans le cas optimal qui nous permettra de tirer le maximum de performances de Cassandra.
III-D-4. Gestion de la cohérence▲
De plus, cette représentation du panier nous permet de relâcher la cohérence.
En effet, Cassandra, sur le modèle de Dynamo créée par Amazon pour gérer les paniers du site marchand, est conçue initialement comme une base cohérente à terme. L'idée est de privilégier la disponibilité et la résistance aux partitions réseau plutôt que la cohérence des données sur tous les serveurs. Amazon préfère ajouter un élément au panier, même s'il n'arrive pas à mettre à jour toutes ses répliques plutôt que de lever une erreur et voir son client potentiel partir finir son achat ailleurs. Les écarts entre les données étant réconciliées par le système par la suite.
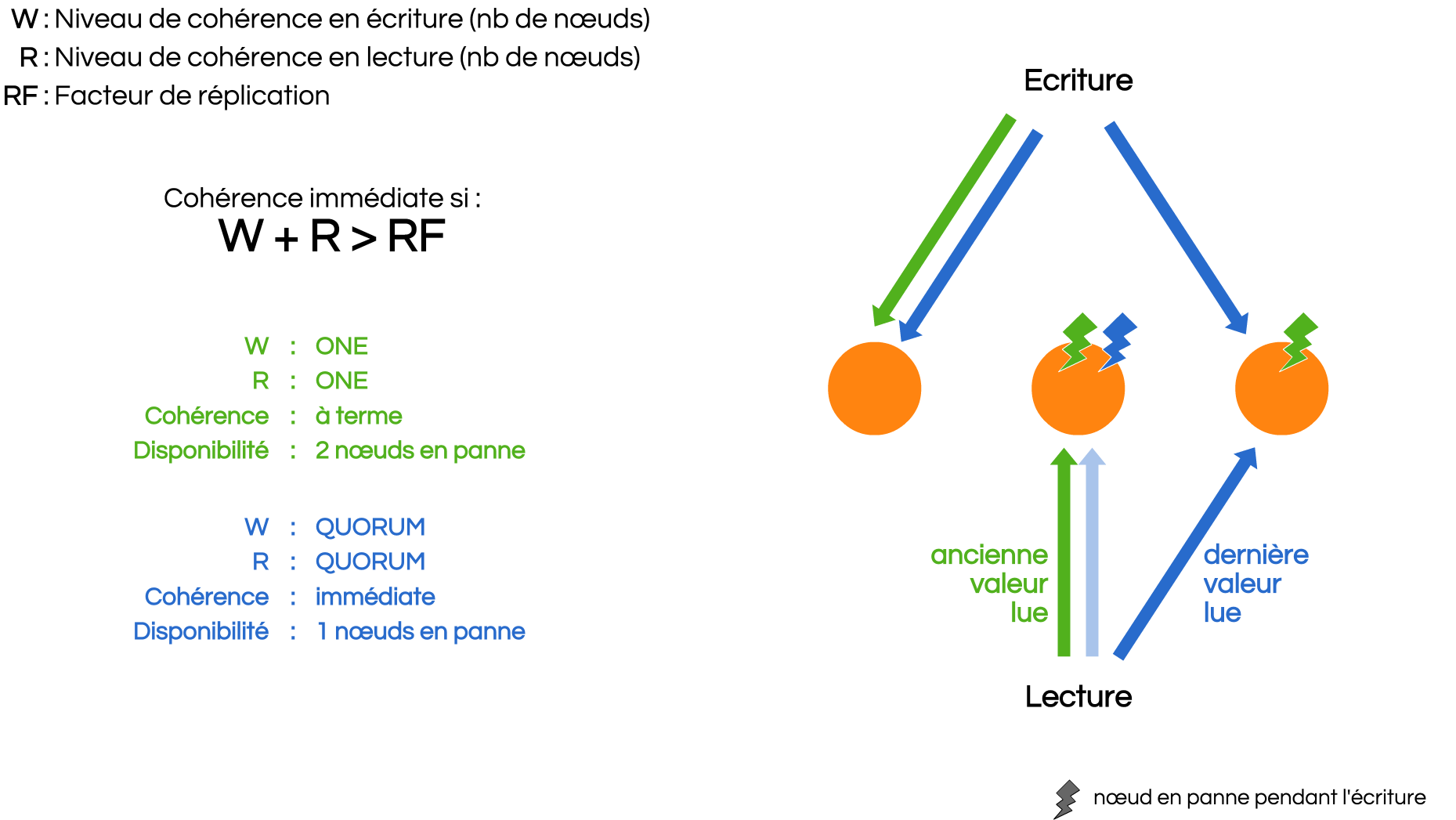
En fait, Cassandra donne la liberté au développeur de choisir s'il veut plus de cohérence ou une plus grande disponibilité. Selon votre cas métier, vous devrez choisir la très haute disponibilité (et la latence d'écriture la plus faible) ou la cohérence immédiate.
Le réglage s'effectue en choisissant le niveau de cohérence de chaque requête. Au moment de l'écriture, le niveau de cohérence est le nombre de nœuds qui ont acquitté l'écriture. Au moment de la lecture, c'est le nombre de nœuds qui ont répondu. Lorsque deux nœuds fournissent une valeur différente, la plus récente est conservée et un mécanisme de réparation se met en place. Les principaux niveaux de cohérence offerts par Cassandra sont ONE, QUORUM et ALL. Souvent utilisés en ONE-ONE pour une cohérence à terme ou QUORUM-QUORUM pour une cohérence immédiate. D'autres combinaisons sont possibles, mais elles sont rares et ne doivent être utilisées que si l'on en maîtrise les conséquences.
IV. Remerciements▲
Cet article a été publié avec l'aimable autorisation de Jérôme Mainaud. L'article original peut être vu sur le blog de la société Ippon.
Nous remercions également Malick Seck pour la mise au gabarit, Franouch pour la relecture orthographique de cet article.
Vous pouvez réagir par rapport à cet article. Commentez ![]()