


I. Introduction▲

Dans cette catégorie, on peut citer (uniquement chez Apache) : ListeFWK

Parmi ces solutions, Spark et Flink semblent très proches :
- compatibilité Hadoop ;
- remplacement de MapReduce ;
- capables de traiter des flux de données temps réel ou des batchs ;
- favorisent les traitements en mémoire (sur disque si nécessaire) ;
- Lambda architecture (plateforme de batch et de streaming).
Cependant on peut noter quelques différences :
- Spark Streaming est une extension de Spark ;
- Flink a été conçu dès le départ pour le temps réel ;
- Spark a été écrit initialement en Scala et supporte Java grâce à des wrappers ;
- Flink a été écrit initialement en Java et supporte Scala grâce à des wrappers ;
- Flink peut exécuter des traitements Hadoop directement (idéal pour une transition en douceur).
Concernant le streaming, cette différence est avant tout conceptuelle, car souvent on va borner le flux temps réel pour produire des résultats intermédiaires.
Pour Flink, un batch est un Stream borné dans le temps, dans le nombre d'éléments à traiter, etc.
Apache Flink comprend :
- des API en Java/Scala pour le traitement par batch et en temps réel ;
- un moteur de transformation des programmes en flots de données parallèles ;
- un moteur d'exécution pour la distribution des traitements sur un cluster.
II. Écosystème Flink▲
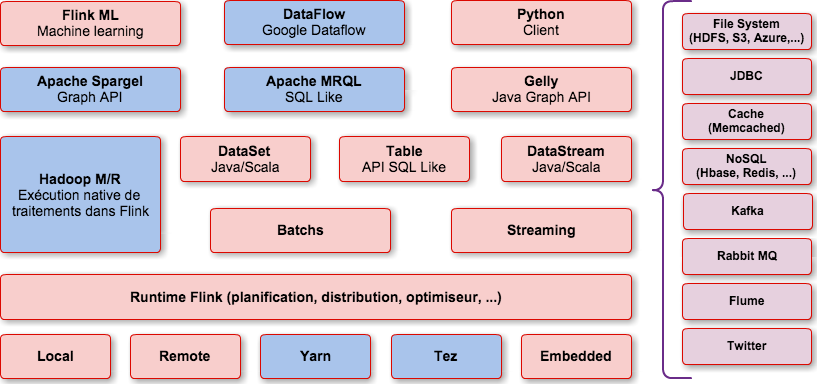
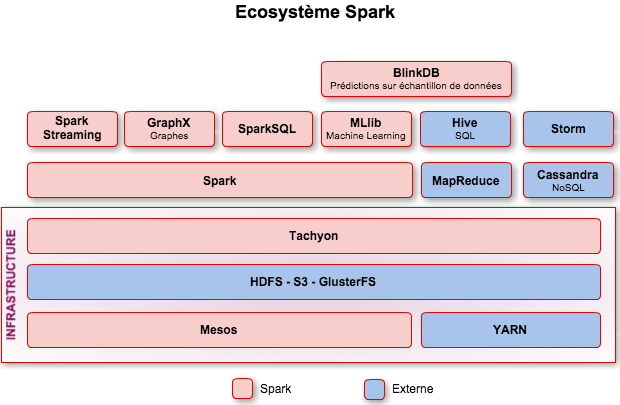
Pour rappel, voici l'écosystème Spark :
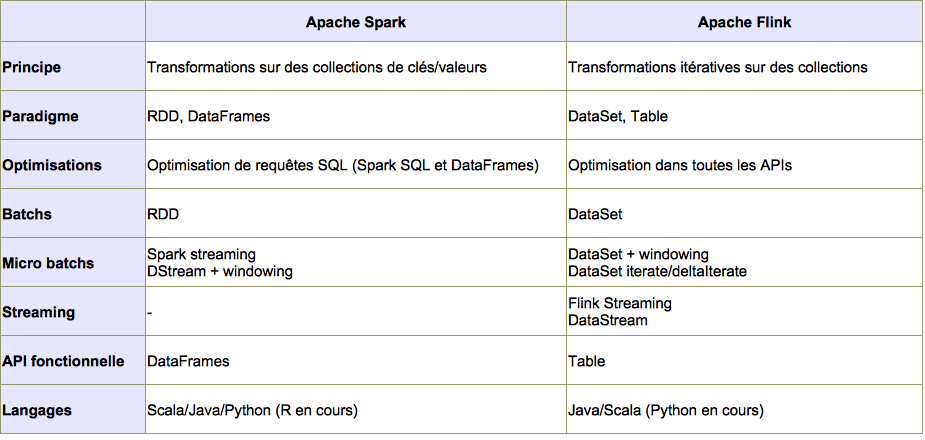
III. Comparaison Spark/Flink▲
III-A. Gestion des clusters▲
Options disponibles avec Spark :
- Standalone, Mesos, Yarn, cloud (EC2, Google DataFlow…).
Options disponibles avec Flink :
- Standalone, Yarn, cloud (EC2, Google DataFlow…), Apache TEZ.
Flink est plus lié à Hadoop (et surtout à Yarn) que Spark.
III-B. Liste des opérations▲
Extrait de la liste des opérateurs disponibles (Flink) :
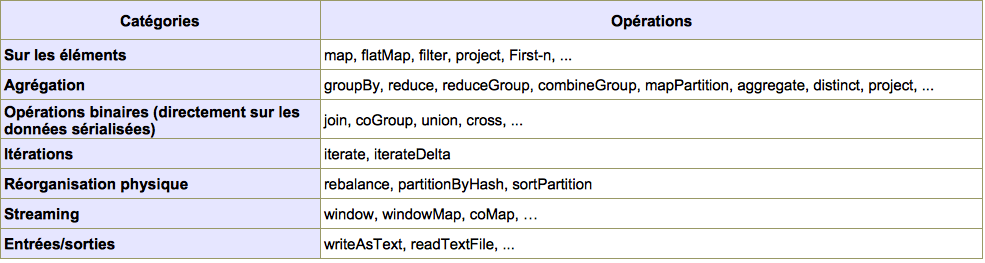
Les opérateurs sont nombreux et s'il y a quelques petites différences entre Flink et Spark, elles sont mineures.
III-C. Exemple de code (batch)▲
Spark
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile(input);
JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split("\\W+")));
JavaPairRDD<String, Integer> counts = words
.mapToPair(w -> new Tuple2<String, Integer>(w, 1))
.reduceByKey((x, y) -> x + y);
counts.saveAsTextFile(output);Flink
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.readTextFile (input);
DataSet<Tuple2<String, Integer>> counts= text
.map(l -> l.split("\\W+"))
.flatMap (
(String[] tokens, Collector<Tuple2<String, Integer>> out) ->
{ Arrays.stream(tokens)
.filter(t -> t.length() > 0)
.forEach(t -> out.collect(new Tuple2<>(t, 1)));
})
.groupBy(0)
.sum(1);
counts.writeAsText(output);
env.execute("Word Count Example");Les codes sont très similaires, on notera cependant quelques différences.
Flink a absolument besoin d'un « sink » (point de sortie) qui peut être :
- affichage du résultat dans la console ;
- sauvegarde dans un fichier ;
- …
III-D. Streaming (micro batch)▲
Dans Flink, tout comme Spark, le choix entre batch et streaming se fait au travers :
- de l'environnement d'exécution (StreamingContext vs StreamExecutionEnvironment) ;
- un type dédié (DStream vs DataStream).
Liste des connecteurs streaming :
- File System (HDFS, S3, Azure…) ;
- JDBC ;
- Cache (Memcached) ;
- NoSQL (Hbase, Redis…) ;
- Kafka ;
- Rabbit MQ ;
- Flume ;
- Twitter ;
- …
Exemple de code (streaming)
public static void main(String[] args) throws Exception {
// set up the execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// get input data (10 tweets here)
DataStream<String> streamSource = env.addSource(new TwitterSource(propertiesPath, 10));
DataStream<Tuple2<String, Integer>> tweets =
// normalize and split each line
streamSource
.map(line -> line.toLowerCase().split("\\W+"))
// convert splitted line in pairs (2-tuples)
.flatMap((String[] tokens, Collector<Tuple2<String, Integer>> out) -> {
// emit the pairs with non-zero-length words
Arrays.stream(tokens).filter(t -> t.length() > 0).forEach(t -> out.collect(new Tuple2<>(t, 1)));
})
// group by the tuple field "0" and sum up tuple field "1"
.groupBy(0).sum(1);
// emit result
tweets.writeAsText(outputPath);
}L'API Streaming de Flink est donc différente de celle de Spark et plus proche de celle d'Apache Storm.
III-E. API fonctionnelle▲
Spark
L'API DataFrames a fait récemment son apparition chez Spark. Le but étant d'offrir une API plus proche du langage SQL et faire la jonction entre Spark et les « Data Analysts ».
L'API DataFrames a été conçue pour les batchs et son utilisation pour les microbatchs demande des manipulations supplémentaires.
Flink
L'API Table est aussi très récente et permet de formaliser les traitements dans une forme proche de la syntaxe SQL.
Cette API est disponible pour le batch et le temps réel et offre une API de haut niveau qui apporte concision et clarté.
Exemple :
ExecutionEnvironment env = ExecutionEnvironment.createCollectionsEnvironment();
TableEnvironment tableEnv = new TableEnvironment();
DataSet<WC> input = ...;
Table table = tableEnv.toTable(input);
Table filtered = table
.groupBy("word")
.select("word.count as count, word")
.filter("count = 2");
DataSet<WC> result = tableEnv.toSet(filtered, WC.class);III-F. Gestion des graphes▲
Spark
Pour la gestion des graphes, Spark s'appuie sur la solution.
Flink
Jusqu'à récemment la gestion des graphes avec Flink était déléguée à Apache Spargel (projet générique).
Un projet nommé Gelly a été lancé afin d'offrir à Flink la gestion des graphes, tout en tirant profit des spécificités de Flink (flots itératifs).
Gelly offre :
- Utilitaires d'analyse de graphes ;
- Traitements itératifs sur les graphes ;
- Algorithmes dédiés aux graphes.
Gelly n'est compatible qu'avec des objets héritant des DataSet (Vertex et Edges) et n'est donc compatible qu'avec les batchs et non les flux temps réels.
Parmi les algorithmes :
- PageRank ;
- Weakly Connected Components ;
- Single Source Shortest Paths ;
- Label propagation.
Gelly est actuellement en bêta et le but à terme étant de remplacer Spargel.
III-G. Machine learning▲
Spark
Spark utilise la bibliothèque MLlib dont la notoriété est grandissante.
Flink
Flink Machine Learning Library (Flink-ML), orienté pipeline inspiré de scikit-learn (framework de Machine Learning écrit en python).
C'est une nouveauté de la version 0.9.
Concepts :
- Transformer : comme le nom l'indique, ce composant va transformer les données (format pour le traitement), mais aussi les filtrer ou les échantillonner ;
- Learner : les learners vont permettre de constituer un modèle dynamique d'apprentissage à partir des données et des algorithmes implémentés ;
- Model : c'est l'élément obtenu à partir des learners, afin de prédire le comportement de données futures.
Flink-ML vise deux objectifs principaux :
- Accessibilité du plus grand nombre au Machine Learning ;
- Performances.
Implémentation des principaux algorithmes de Machine Learning optimisés spécifiquement pour Flink.
Flink-ML dispose des algorithmes suivants :
- Classification ;
- Regression (Logistic regression) ;
- Clustering (k-Means) ;
- Recommendation (Alternating least squares).
Il existe d'autres algorithmes, mais uniquement en Scala pour le moment (est-ce une tentative de séduction des « Data Analysts » ?).
Une intégration avec Mahout DSL comme moteur d'exécution est en cours.
III-H. Maturité du produit▲
Évidemment Flink est moins mature que Spark (bien que les deux projets soient nés en 2009).
Contributeurs respectifs :
- Spark : 540 contributeurs ;
- Flink : 94 contributeurs.
Spark dispose d'un net avantage, mais Flink a autant, voire plus de contributeurs que des projets comme Cassandra ou Mesos).
Flink souffre de quelques lacunes :
- pour utiliser les lambda, il faut absolument utiliser le compilateur Eclipse JDT ;
- pas de support des génériques dans les chemins de fichiers ;
- …
Partenariats, clients… :
- Flink est déployable sur Hadoop Data Platform d'HortonWorks et des évolutions sont en cours pour Cloudera (fichier de configuration Hadoop non compatible) ;
- Cloud Google : disponibilité de Flink comme runtime pour Google Cloud Dataflow ;
- Clients expérimentant Flink : Amadeus, Spotify…
III-I. Configuration▲
Le paramétrage dans Flink peut se faire de deux façons :
- fichier de configuration « flink-conf.yaml » dans le répertoire $Flink_HOME/conf ;
- ou depuis l'API depuis version 0.9.0 M1.
III-J. Optimisations▲
L'optimisation des traitements est un point important de Flink. Par analogie, on peut voir l'optimiseur comme celui d'une base de données.
Le meilleur « chemin » est choisi au moment de l'exécution en fonction de paramètres et en privilégiant le traitement le plus rapide.
Pour faire ce choix, l'optimiseur analyse principalement :
- les types de données ;
- les fonctions utilisées.
Il intervient à la fois pour les traitements batch et les traitements en temps réel.
Ainsi pour une méthode de type join utilisée dans le programme, Flink peut décider d'utiliser :
- un partitionnement ou non des DataSet impliqués ;
- un hash join ou un merge join avec tri ;
- …
Une grosse partie a aussi lieu au moment des itérations :
- Mise en cache des données constantes
- Les opérations les plus coûteuses sont déplacées en dehors de la boucle ;
- …
La plupart du temps l'optimiseur va faire les bons choix sans que vous ayez à vous en préoccuper, toutefois il est possible de forcer la stratégie d'exécution.

III-K. Tolérance à la panne▲
Les systèmes NoSQL sont souvent classés en fonction du respect du théorème CAP ou BASE qui est plus spécifique.
Les systèmes de traitements distribués comme Spark ou Flink sont souvent catalogués selon les garanties de livraison/traitement des messages :

Idéalement, nous souhaitons un système de type « Exactly once delivery/processing ».
Mais sans rentrer trop dans les détails, sachez que pour ce genre de système :
- Exactly-once delivery est impossible en conditions dégradées ;
- Exactly-once processing of messages est possible en conditions dégradées.
Mais le plus important est le traitement unique d'un message, soit le respect de la règle « Exactly-once processing ».
Comparaison Spark/Flink :
- Spark : « exactly once » en conditions normales et « at least once » en conditions dégradées ;
- Flink : « exactly once » en condition normales et dégradées (en cours de finalisation).
Les deux systèmes utilisent la même technique : la persistance des messages dans un système externe (Apache Kafka), mais ont une approche différente dans son utilisation :
- de manière transparente pour Flink ;
- activé par l'utilisateur pour Spark (Write Ahead Log).
Les deux systèmes sont confrontés aux mêmes contraintes, la réplication des données en mémoire (redondance pour faciliter le fail over) :
- Spark conseille de la désactiver (et donc d'utiliser les disques) pour garantir la sémantique exactly-once.
La tolérance à la panne côté Flink est en cours de développement et il est trop tôt pour vérifier si les promesses sont tenues et quelles en sont les limites.
IV. Avantages de Flink▲
IV-A. Son API très fonctionnelle▲
L'exemple suivant montre que l'on peut utiliser directement le nom des champs des structures dans les traitements de type filtre ou d'agrégation.
class Impression {
public String url;
public long count;
}
class Page {
public String url;
public String topic;
}
DataSet<Page> pages = ...;
DataSet<Impression> impressions = ...;
DataSet<Impression> aggregated = impressions.groupBy("url").sum("count");
pages.join(impressions).where("url").equalTo("url").print();IV-B. Itérations▲
Flink propose deux types d'itérations :
- Itérations simples ;
- Delta-itérations.
La première facilite la gestion de flux successifs et l'agrégation des résultats.
La deuxième vise avant tout les performances.
Les itérations sont de moins en moins coûteuses au fur et à mesure des traitements.
L'inconvénient étant qu'il faut un certain nombre d'itérations avant d'obtenir le résultat final, mais ensuite si les entrées évoluent, seules les nouvelles seront traitées (delta-itérations).
IV-C. Exemple d'itérations▲
public class IterateDummyExample {
static int max_iteration = 20;
static int max_sequence = 100;
static final Long iteration = new Long("1");
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// on construit un DataSet de type ([1, (1,1)], [2, (1,2)], ... )
// soit V0, n, V0Exp(n) : valeur initiale, nb factorisation, resultat
DataSet<Tuple3<Long, Long, BigDecimal>> initialInput = env.generateSequence(1, max_sequence).map(
l -> new Tuple3<Long, Long, BigDecimal>(l, iteration, BigDecimal.valueOf(l)));
// On définit le nombre d'itérations
IterativeDataSet<Tuple3<Long, Long, BigDecimal>> iter = initialInput.iterate(max_iteration - 1);
// Calcul sur le DataSet à chaque itération
DataSet<Tuple3<Long, Long, BigDecimal>> result = iter.closeWith(iter
.map(t -> new Tuple3<Long, Long, BigDecimal>(t.f0, t.f1 + 1, BigDecimal.valueOf(t.f0).multiply(t.f2))));
// Affichage du résultat
result.print();
env.execute("Calcul itératif exposant");
// System.out.println(env.getExecutionPlan());
}
}Les itérations existent avec Spark, mais il faut faire des checkpoints (sauvegarde sur disque ou en mémoire).
Cela est disponible à la fois pour les batchs et les microbatchs (RDD ou DStream).
Exemple d'itération avec Spark :
JavaRDD lines = sc.textFile(...);
JavaRDD points = lines.map(new ParsePoint()).cache();
int ITERATIONS = ...;
for (int i = 0; i < ITERATIONS; i++) {
// computation with rdd points . . .
}V. Performances▲
Flink affirme être 100 fois plus rapide qu'Hadoop, on a l'habitude avec Spark.
Mais Flink affirme être 2,5 fois plus rapide que Spark, ce qui est moins courant, sur un cas de grep de 1 To de Logs (cf. http://fr.slideshare.net/GyulaFra/flink-apachecon).
D'après mes observations, cet avantage se confirme que ce soit en batch et en streaming.
Pour atteindre ces performances, Flink se base sur trois points :
- L'optimiseur qui décide de la meilleure stratégie d'exécution ;
- Sa gestion de la mémoire ;
- La sérialisation et sa capacité à traiter les données sérialisées (sans les désérialiser donc).
V-A. Gestion de la mémoire▲
Flink gère lui-même la mémoire (sans la déléguer complètement à la JVM).
C'est dans un espace dédié de la Heap que Flink fait ses traitements.
L'avantage est d'éviter les fameuses OutOfMemoryException et d'être moins impacté par les temps de pause dus au passage du Garbage Collector.
V-B. Sérialisation▲
Flink propose son propre système de sérialisation et y recourt lourdement.
Cette implémentation est très performante.
Ajouté à sa capacité à opérer des traitements sur des données déjà sérialisées, Flink réduit considérablement les échanges réseau ainsi que l'occupation mémoire.
Avec Spark, la sérialisation est beaucoup plus rare et n'intervient que lorsqu'elle est strictement nécessaire (sauvegarde sur disque…).
Afin d'améliorer les performances, Spark a lancé le projet Tungsten qui a pour objectif une meilleure gestion de la mémoire, les opérations sur les données binaires, etc.
V-C. Plan d'exécution▲
Un aspect important dans l'optimisation et la compréhension d'un traitement est la possibilité d'afficher le plan d'exécution réel (i.e. après passage de l'optimiseur) d'un programme.
Flink propose deux méthodes pour afficher le plan d'exécution.
V-C-1. Dans l'interface web▲
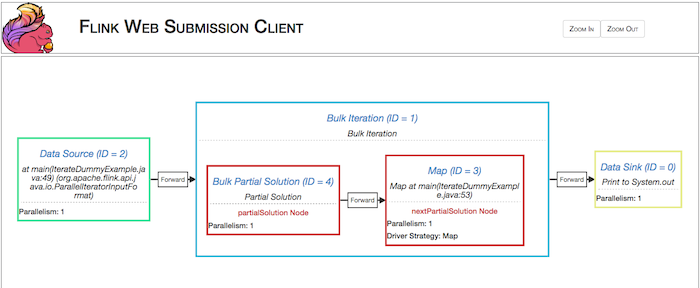
V-C-2. Par l'API▲
Remplacer
env.execute();
par
System.out.println(env.getExecutionPlan());Cette méthode permet l'affichage au format JSON des informations sur l'exécution d'un traitement Flink.
Extrait :
{"id":4,"type":"pact","pact":"GroupReduce","contents":"SUM(1), at main(java8WC.java:23","parallelism":"4",
"predecessors":[{"id":5,"ship_strategy":"Forward"}],"driver_strategy":"Sorted Combine",
"global_properties":[{"name":"Partitioning","value":"RANDOM_PARTITIONED"},{"name":"Partitioning Order","value":"(none)"},{"name":"Uniqueness","value":"not unique"}],
"local_properties":[{"name":"Order","value":"(none)"},{"name":"Grouping","value":"not grouped"},{"name":"Uniqueness","value":"not unique"}],
"estimates":[{"name":"Est. Output Size","value":"(unknown)"},{"name":"Est. Cardinality","value":"26.52 M"}],
"costs":[{"name":"Network","value":"0.0"},{"name":"Disk I/O","value":"0.0"},{"name":"CPU","value":"0.0"},{"name":"Cumulative Network","value":"0.0"},{"name":"Cumulative Disk I/O","value":"754.12 M"},{"name":"Cumulative CPU","value":"0.0"}],
"compiler_hints":[{"name":"Output Size (bytes)","value":"(none)"},{"name":"Output Cardinality","value":"(none)"},{"name":"Avg. Output Record Size (bytes)","value":"(none)"},{"name":"Filter Factor","value":"(none)"}]}Il faut ensuite utiliser le fichier HTML « tools/planVisualizer.html ».

On voit :
- le niveau de parallélisation de chaque étape ;
- les étapes ajoutées par l'optimiseur (ici un tri sur la clé du DataSet (Hash partition)) ;
- le coût de chacune des étapes (CPU, réseau, i/o) en double cliquant.
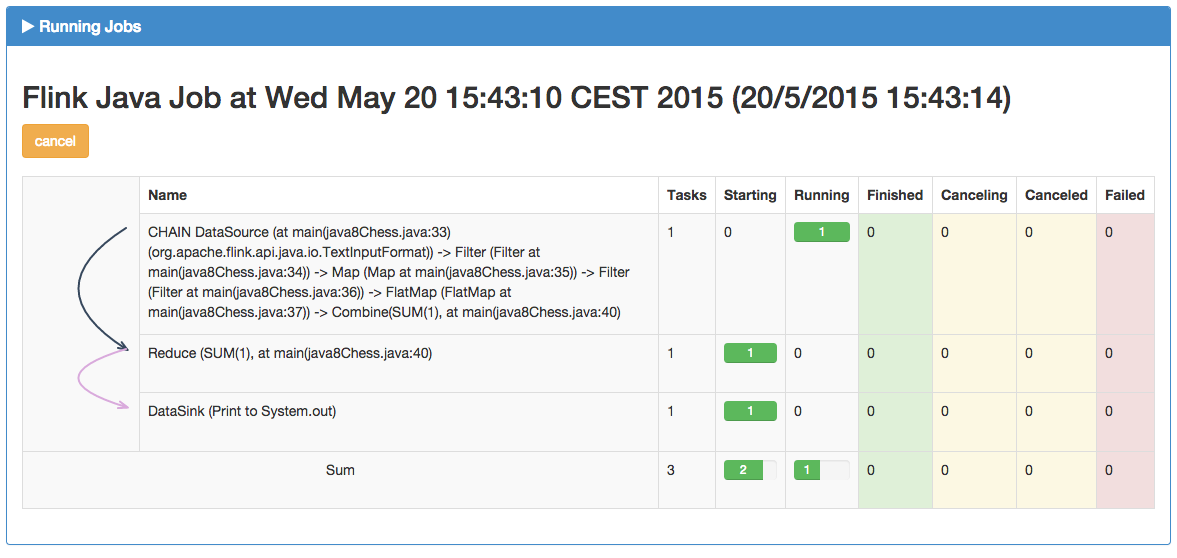
VI. Dashboard▲
Tout comme Spark, Flink propose une application web de suivi et de déploiement des traitements sur le cluster.
Visualisation d'un traitement et décomposition en étapes :
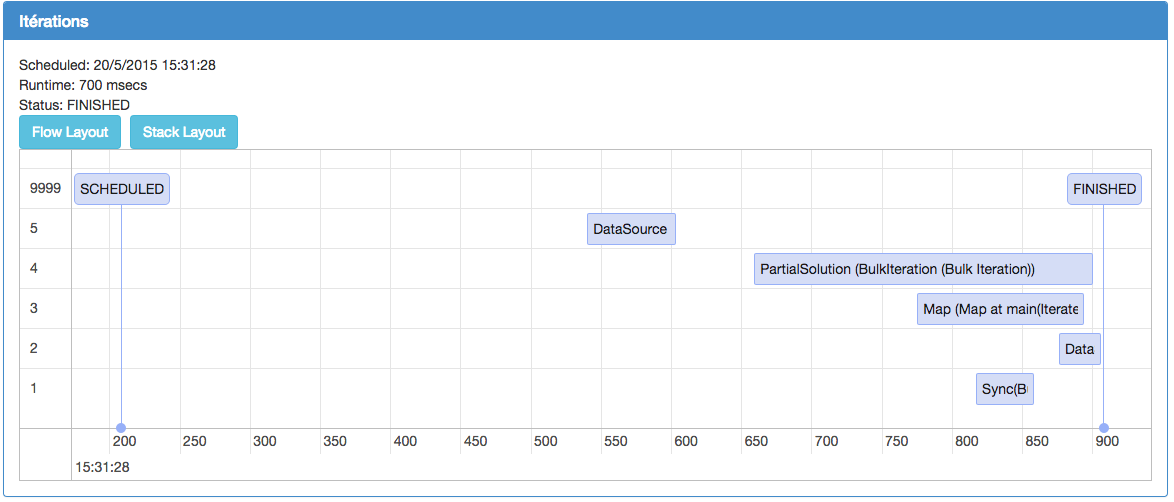
Une fois le traitement terminé, il est possible de visualiser les durées de chacune des étapes :
VII. Roadmap des évolutions▲

VIII. Conclusion▲
Ce n'est pas un énième framework BigData, car Flink apporte de vraies nouveautés en termes de philosophie et d'API.
- Spark est un framework de batch capable de faire du microbatch
- Flink est un framework de streaming capable de faire du microbatch
De fait, les cas d'utilisation d'Apache Flink sont sans doute plus proches de Storm que de Spark.
Cependant leurs API et leurs paradigmes étant très proches, difficile de ne pas faire de rapprochement.
Une autre différence importante étant la gestion du cluster :
- Spark délègue la gestion des ressources à Mesos ;
- Flink a son propre système de gestion des ressources.
Toutefois la maturité des deux solutions n'est pas comparable :
- même s'il existe des cas d'utilisation de Flink en production, ils sont encore loin des chiffres de Spark, et ce même si, Flink a été testé avec succès sur pratiquement 200 nœuds.
Enfin, il existe un point qui ne facilite pas l'adoption de Flink, c'est l'absence de REPL (Read-Eval-Print-Loop), la fameuse évolution de Java 9 qui permet de lancer des commandes dans une console et donc facilite l'adoption par des profils non développeurs comme les « Data Scientists ».
Difficile de ne pas aborder le cas des performances qui offre un net avantage à Flink vis-à-vis de Spark dont c'est pourtant un des points forts.
IX. Remerciements▲
Cet article a été publié avec l'aimable autorisation de Christophe Parageaud. L'article original peut être vu sur le blog de la société Ippon.
Nous remercions également Vincent Viale pour la mise au gabarit, Claude Leloup pour la relecture orthographique de cet article.
Vous pouvez réagir par rapport à cet article. 1 commentaire ![]()